今回は、教師なし学習の主要な手法であるクラスタリングについて解説します。
クラスタリングの中でも特に、DBSCANを詳しく説明します。
また、DBSCANをPythonで実装する方法も解説していきます。
動画で詳しく学習したい方はこちらもおすすめ
クラスタリングとは
データを自然なグループに分割するプロセスを指します。
教師なし学習のひとつであり、画像データを特徴量ごとに分類するときなど、様々な分野で活用されています。
DBSCAN
クラスタリングの手法のひとつである、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)について紹介します。
DBSCANとは
DBSCANは、データの密度をベースとして、クラスタリングするアルゴリズムです。
データの密度からノイズや外れ値を検出し、クラスタに属さないデータとして扱うことが可能です。
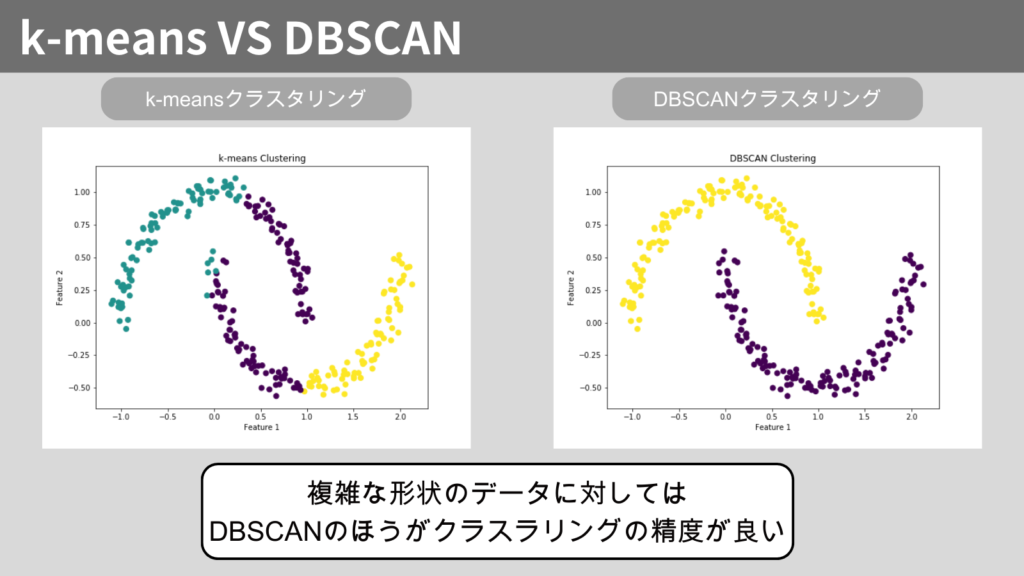
密度でクラスタリングすることから、他のクラスタリング手法であるk-meansクラスタリングよりも、複雑な形状のデータにも対応可能です。
以下は、k-meansとDBSCANでクラスタリング結果を比較した図です。
パラメータ
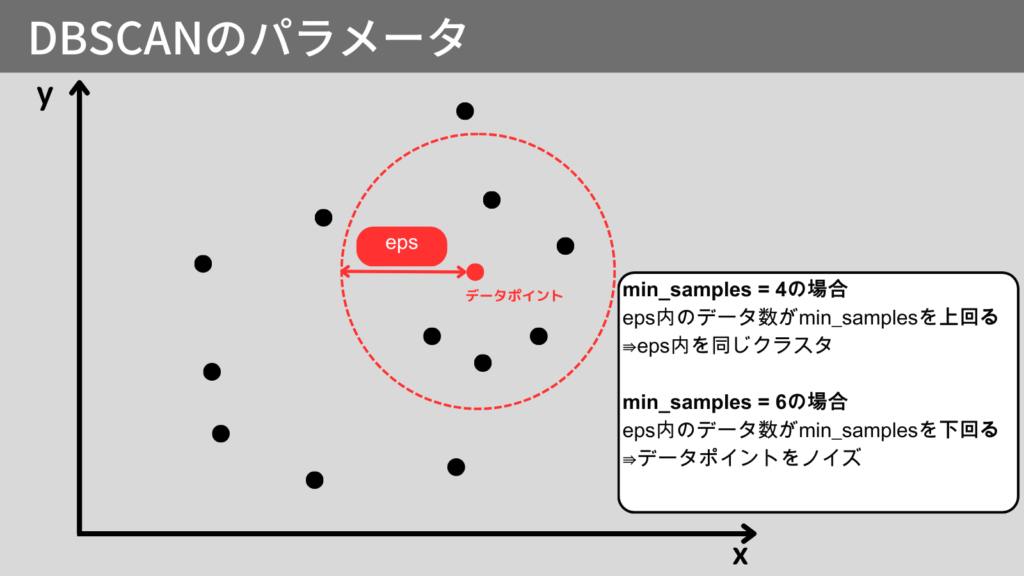
DBSCANには、主に2つの重要なパラメータが存在します。
- eps
\( \epsilon\)(イプシロン) 各データ間の半径(距離)。\( \epsilon \)内に存在するデータが一定数(min_samples)以上であれば、そのデータを「コアポイント」とする - min_samples
データがコアポイントと判定される最小のデータ数
特徴
DBSCANのメリット・デメリットをまとめると以下の通りです。
メリット
- クラスタ数を事前に決定する必要がない
- ノイズの除去
- 複雑な形状なクラスタにも対応
デメリット
- パラメータの設定が結果に大きく影響
- 計算コストが高い
Python実践 DBSCAN
それではPythonを使用し、DBSCANクラスタリングを実装してみましょう!
scikit-learnライブラリを使用します。
使い方は以下の通りです。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)
eps: イプシロン、距離の閾値min_samples: 最小のデータの数の閾値
こちらを使用したサンプルコードは以下の通りです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
# サンプルデータの生成
X, _ = make_moons(n_samples=300, noise=0.05, random_state=42)
# DBSCANの実行
dbscan = DBSCAN(eps=0.2, min_samples=5)
clusters = dbscan.fit_predict(X)
# 結果の可視化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis', s=50)
plt.title("DBSCAN Clustering")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
実行結果
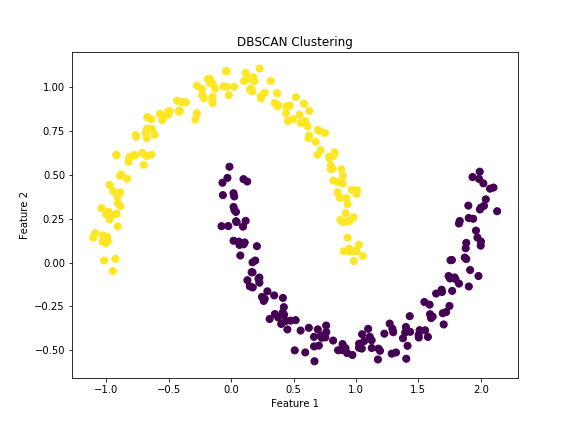
データが三日月型の複雑の分布の場合でも、きれいにクラスタリングされていることがわかリます。
まとめ
クラスタリングの中でも有名なDBSCANについて解説しました。
DBSCANは、データの密度にベースにクラスタリングしていくのが特徴です。複雑な形状のデータのクラスタリングに向いています。
DBSCANをPythonで実装する方法は以下の通りです。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)
ここまで読んでくださりありがとうございます。