
今回は、最適なモデルを作成するために必要なグリッドサーチについて解説します。
また、Pythonを使用しグリッドサーチを実装する方法をあわせて説明します。
動画で詳しく学習したい方はこちらもおすすめ
グリッドサーチとは
グリッドサーチ(Grit Search)は、最適なハイパーパラメータを見つけるための手法です。
複数のハイパーパラメータの組み合わせを網羅的に探索します。
すべての組み合わせを試行し、最も評価の良いパラメータを見つけます。
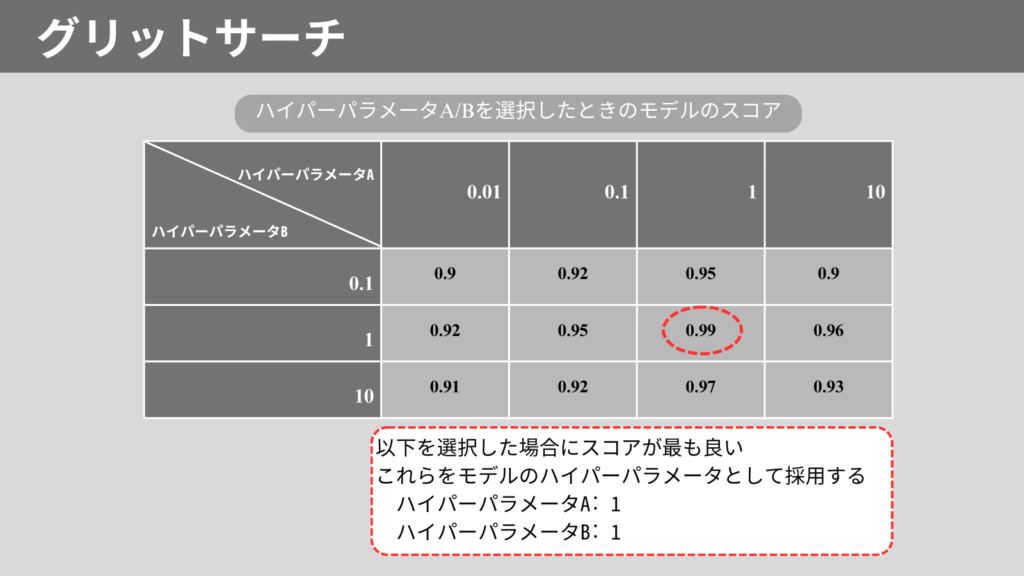
ハイパーパラメータとは
ハイパーパラメータとは、モデルに対して設定するパラメータです。
モデルの性能にも影響を与えます。
わかりやすい例でいうと、決定木の”深さ”(max_depth)が該当します。
また、このようなハイパーパラメータをモデルの性能を最適化するために、調整することをハイパーパラメータチューニングといいます。
交差検証を用いたグリッドサーチ
ハイパーパラメータを最適化する「グリッドサーチ」と、モデルの性能を評価する「交差検証」は同時に使用されることが多いです。
以下手順で実施します。
- グリッドサーチで複数のハイパーパラメータを組み合わせる
- 組み合わせひとつひとつに対し交差検証を実施
- 最もスコアの良い組み合わせを選択

Python実践 グリッドサーチ
それでは、Pythonを使用しグリッドサーチを実装してみましょう!
グリッドサーチと交差検証を組み合わせた方法を紹介します。
以下方法で、グリッドサーチと交差検証を組み合わせて実装します。
sklearnのmodel_slectionモジュールを使用します。
from sklearn.model_selection import GridSearchCV
GridSearchCV(estimator, param_grid, cv, scoring, n_jobs)
GridSearchCVのパラメータの説明は以下の通りです。
| パラメータ | 説明 | デフォルト |
|---|---|---|
| estimator | モデル | 必須 |
| param_grid | 辞書型のハイパーパラメータ | 必須 |
| cv | 交差検証の分割数 | 5 |
| scoring | 評価指標(accuracy=正解率, precision=適合率… ) | None |
| n_jobs | 並列処理数(-1 で全CPU使用) | None |
SVM(サポートベクターマシン)モデルに対し、グリッドサーチおよび交差検証を実施したサンプルコードです。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# データの読み込み
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# モデルの定義
model = SVC()
# グリッドサーチのパラメータ設定
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1],
'kernel': ['rbf']
}
# グリッドサーチの実行
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 最適なパラメータとスコアの表示
print("Best parameters:", grid_search.best_params_)
print("Best score:", grid_search.best_score_)
実行結果
Best parameters: {'C': 1, 'gamma': 1, 'kernel': 'rbf'}
Best score: 0.9583333333333334まとめ
最適なモデルを作成するために必要なグリッドサーチについて解説しました。
グリッドサーチは、複数あるモデルのハイパーパラメータから最適な組み合わせを選択する手法です。
グリッドサーチは交差検証と合わせて使用されることが多く、その手法をPythonで実装する方法は以下の通りです。
from sklearn.model_selection import GridSearchCV
GridSearchCV(estimator, param_grid, cv, scoring, n_jobs)
ここまで読んでくださりありがとうございます。









