組み込み開発では、ソフトウェアが完全に停止してしまう「フリーズ」への対策が欠かせません。
その代表的な仕組みがウォッチドッグタイマです。
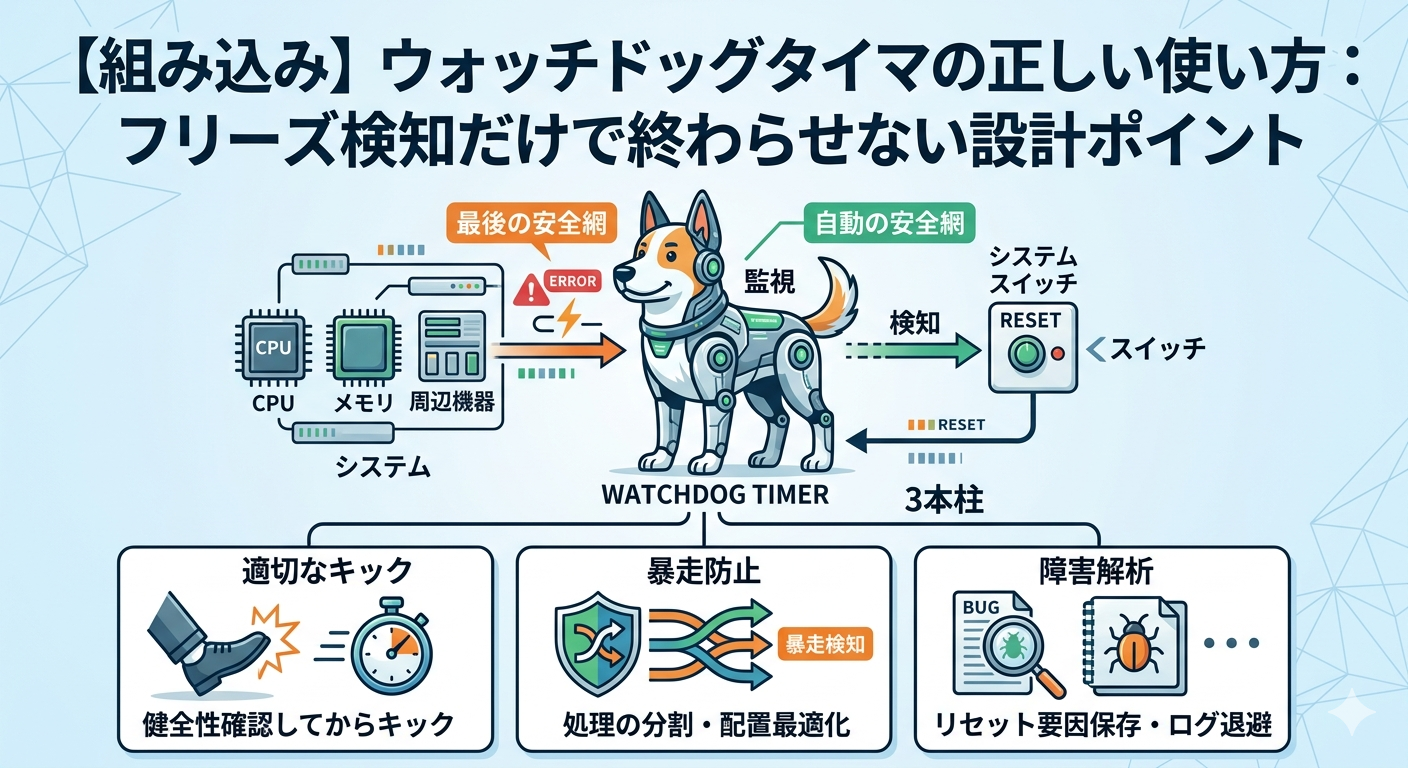
ウォッチドッグタイマは、一定時間ごとにソフトウェアが正常動作していることを示せなければ、システムをリセットするための機能です。
ただし、単に「定期的にキックすればよい」と考えると、異常を見逃す設計になりやすい点に注意が必要です。
この記事では、ウォッチドッグタイマの基本に加えて、どこでキックすべきか、暴走を隠してしまう実装をどう避けるか、さらに障害解析とセットでどう設計するかまで整理していきます。
ウォッチドッグタイマとは
ウォッチドッグタイマは、一定時間内にソフトウェアから更新処理(キック、リフレッシュ)が行われなかった場合に、CPUやシステムをリセットする仕組みです。
例えば、以下のような異常時に役立ちます。
- 無限ループに入って処理が戻らない
- デッドロックでタスクが停止する
- 割り込みの暴走でメイン処理が進まない
- 想定外のハングアップで通信応答が止まる
つまり、ウォッチドッグタイマは異常を未然に防ぐものというより、異常発生後に復帰するための最後の安全網です。
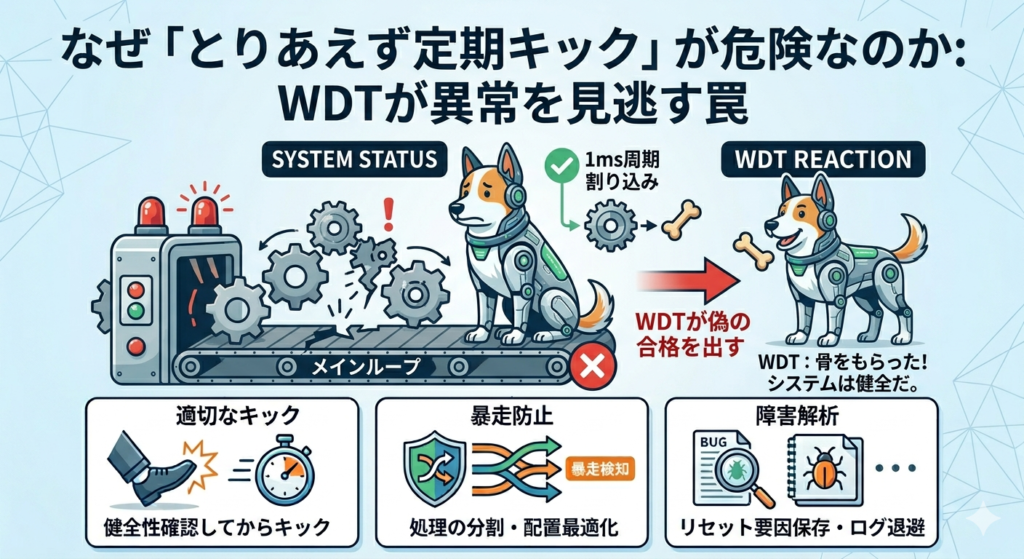
なぜ「とりあえず定期キック」が危険なのか
ウォッチドッグ導入時によくある失敗が、タイマ割り込みや周期タスクの中で無条件にキックしてしまう実装です。
一見すると安定して動きそうですが、この方法には問題があります。
アプリケーション本体が止まっていても、キック処理だけが動き続ければ、ウォッチドッグは異常を検知できません。
たとえば次のような状態です。
- メインループは停止している
- 通信処理は応答していない
- センサ値更新も止まっている
- しかし1ms周期割り込みだけは生きており、そこでキックしている
この場合、システムは実質故障しているのに、リセットされず異常が継続します。
つまり、キック処理が生きていることと、システム全体が正常であることは別です。
ウォッチドッグはどこでキックすべきか
基本方針はシンプルで、「必要な処理が一巡し、システムが健全だと判断できた地点でキックする」ことが重要です。
メインループ末尾でキックする
ベアメタル構成であれば、もっともわかりやすいのはメインループの最後でキックする方法です。
while (1) {
poll_sensor();
process_command();
update_output();
communication_task();
if (system_is_healthy()) {
kick_watchdog();
}
}この形であれば、どれかの処理で止まった場合にキックまで到達できず、異常を検出できます。
RTOSでは複数タスクの生存確認をまとめる
RTOS(リアルタイムOS)を使う場合は、1つのタスクだけを見ていても不十分です。
通信タスク、制御タスク、監視タスクなど、重要タスクがそれぞれ動作していることを確認してからキックする設計が有効です。
例えば、各タスクが一定周期でハートビートを更新し、監視タスクがまとめて確認します。
- 制御タスクが期限内に動いたか
- 通信タスクが詰まっていないか
- センサ取得タスクが更新を続けているか
これらが揃ったときだけウォッチドッグを更新すれば、一部タスクだけが生き残る故障も検出しやすくなります。
暴走を隠さないための設計ポイント
ウォッチドッグは入れるだけでは意味がなく、異常を隠さない設計が大切です。
キック処理をあちこちに置かない
複数箇所から自由にキックできる設計は避けたいところです。
原因追跡が難しくなり、異常時でもどこかがキックしてしまう可能性があります。
キックは原則として1か所に集約し、そこに至る条件を明確にした方が安全です。
長時間処理は分割する
フラッシュ書き込みや大きな通信待ちなど、正常でも時間がかかる処理があります。
このとき、タイムアウトを長くしすぎると異常検知が鈍くなります。
対策としては次のような方法があります。
- 長時間処理を小さな状態遷移に分割する
- 途中で進捗を監視できるようにする
- ブロッキング待ちではなくタイムアウト付きで処理する
ウォッチドッグに合わせて設計を見直すと、ソフト全体の健全性も上がります。
タイムアウト値は「最悪実行時間」基準で決める
短すぎる設定では正常時にも誤リセットが発生します。
逆に長すぎると、異常復帰までに時間がかかります。
そのため、ウォッチドッグの周期は以下を踏まえて決めるのが実務的です。
- 通常時の処理周期
- 最悪実行時間
- 一時的な負荷上昇
- 許容できる停止時間
経験則だけで決めるのではなく、負荷試験やログで妥当性を確認するのが無難です。
障害解析とセットで考える
ウォッチドッグで自動復帰できても、なぜ落ちたのかが分からなければ再発防止につながりません。
そのため、リセット前後の情報を残す設計が重要です。
リセット要因を保存する
多くのマイコンでは、リセット原因レジスタを参照できます。
起動直後に以下の情報を不揮発領域やRAM退避領域へ保存しておくと、調査しやすくなります。
- ウォッチドッグリセットかどうか
- 発生回数
- 直前の状態番号
- 最後に実行したタスクやイベント
- エラーコード
最小限の障害ログを持つ
本格的なダンプ取得が難しくても、最低限のログだけで有用性は大きく変わります。
例えば、以下のような情報があるだけでも役立ちます。
- 最後に通過した関数ID
- 通信中だったコマンド種別
- センサ初期化中か、制御中かといった状態
- 直前の異常カウンタ
「落ちたら再起動する」だけで終わらせず、次回起動時に手がかりを残すことが大切です。
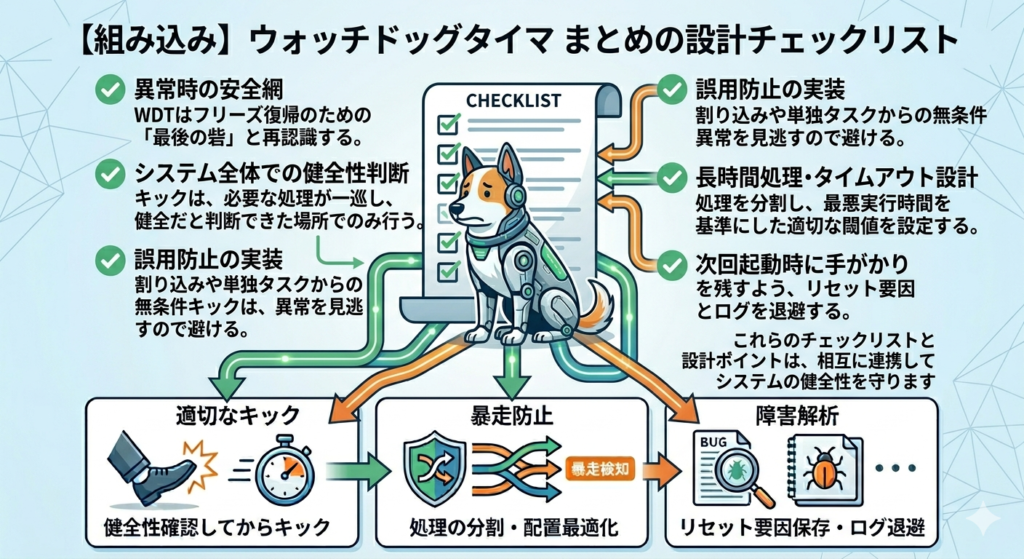
まとめ
ウォッチドッグタイマは、組み込み機器の信頼性を高めるうえで重要な仕組みです。
ただし、単純に定期キックするだけでは、本来検知したい異常を見逃すことがあります。
今回のポイントをまとめると、次の通りです。
- ウォッチドッグは異常時に復帰するための安全網
- キックは「システム全体が正常」と判断できる場所で行う
- 割り込みや単独タスクからの無条件キックは避ける
- 長時間処理やタイムアウト設計も含めて見直す
- リセット原因や直前状態を保存し、障害解析につなげる
実務では、ウォッチドッグは「入れたから安心」ではなく、どう検知し、どう復帰し、どう原因を追うかまで含めて設計するものです。
この視点を持っておくと、現場でのトラブル対応力がかなり変わってきます。