今回は、統計学の基本である範囲、四分位数、分散、標準偏差を
Pythonで求める方法を紹介します。
目次
散布度とは
データの散らばりを示す指標のことです。
平均値だけではみえてこないデータの散らばりを測定することで、
データの特性を知ることができます。
散布度の主な指標です。
- 範囲
- 四分位数
- 分散
- 標準偏差
これらの指標をPythonで求める方法を説明していきます。
使用するデータ
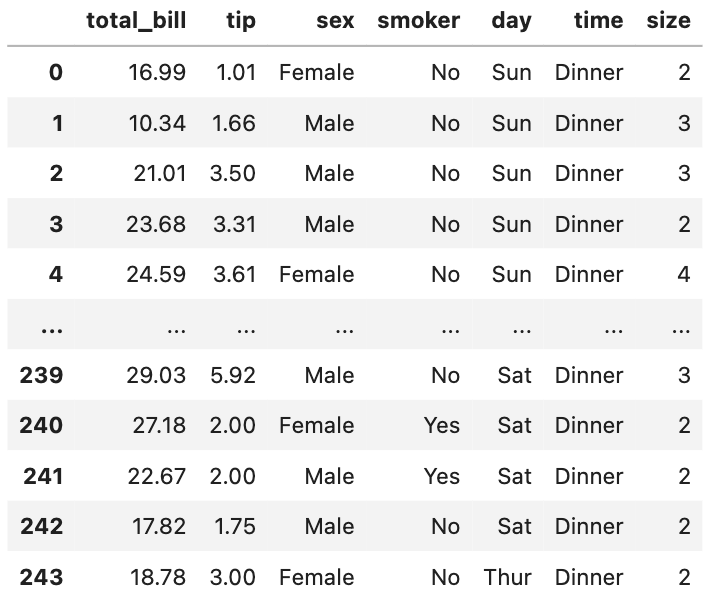
今回は、tipsのデータセットを使用します。
tipsは、機械学習や統計学の分野でサンプルデータとして使用されるレストランのお会計に関するデータセットです
範囲(range)
範囲は 最大値 – 最小値 で求めることができます。
範囲は外れ値の影響を受けやすい指標です。
範囲をPythonで求める方法は以下の通りです。
- np.max() – np.min()
- df[’column’].max() – df[’column’].min()
具体的なサンプルコードは以下です。
import numpy as np
import seaborn as sns
# データの準備
df = sns.load_dataset('tips')
# numpyを使用して求める方法
range_tip_np = np.max(df['tip']) - np.min(df['tip'])
print(range_tip_np)
# データフレームを使用
range_tip_df = df['tip'].max() - df['tip'].min()
print(range_tip_df)実行結果
9.0
9.0四分位数(quartile)
データの中央値を中心にデータの25%(第一四分位数)、75%(第三四分位数)を示す指標です。
四分位数は、範囲よりも外れ値の影響を受けにくい指標です。
四分位数をPythonで求める方法は以下の通りです。
- np.quantile(data, [0.25, 0.5, 0.75])
- df[’column’].quantile([0.25, 0.5, 0.75])
具体的なサンプルコードは以下の通りです。
import numpy as np
import seaborn as sns
# データの準備
df = sns.load_dataset('tips')
# numpyを使用
quarntile_tip_np = np.quantile(df['tip'], [0.25, 0.5, 0.75])
print("numpy:", quarntile_tip_np)
# データフレームを使用
quarntile_tip_df = df['tip'].quantile([0.25, 0.5, 0.75])
print("データフレーム:")
print(quarntile_tip_df)実行結果
numpy: [2. 2.9 3.5625]
データフレーム:
0.25 2.0000
0.50 2.9000
0.75 3.5625
Name: tip, dtype: float64分散(variance)
分散は、データが平均からどれくらい離れているかを示す指標です。
分散をPythonで求める方法は以下の通りです。
- np.var()
具体的なサンプルコードは以下の通りです。
import numpy as np
import seaborn as sns
# データの準備
df = sns.load_dataset('tips')
var_tip = np.var(df['tip'])
print(var_tip)実行結果
1.9066085124966428標準偏差(Standard Deviation)
標準偏差は、分散の平方根をとった指標です。
標準偏差をPythonで求める方法は以下の通りです。
- np.std()
import numpy as np
import seaborn as sns
# データの準備
df = sns.load_dataset('tips')
std_tip = np.std(df['tip'])
print(std_tip)実行結果
1.3807999538298958まとめ
今回は、統計学の基本である範囲、四分位数、分散、標準偏差をPythonで求める方法を紹介しました。
これら散布度は統計の基本中の基本ですので、覚えていきましょう!
ここまで読んでくださりありがとうございます。
参考
おすすめ教材
米国データサイエンティストが教える統計学超入門講座【Pythonで実践】

他のUdemyの講座が気になる方はこちら

Pythonデータサイエンスハンドブック Jupyter、NumPy、pandas、Matplotlib、scikit-learnを使ったデータ分析、機械学習ー [ Jake VanderPlas ]
楽天ブックス
¥4,620 (2026/05/21 06:35時点 | 楽天市場調べ)