
今回は統計学の重要な概念である、母集団と標本の関係を説明します。
また、Pythonで標本抽出、および標本分布を作成する方法を紹介します。
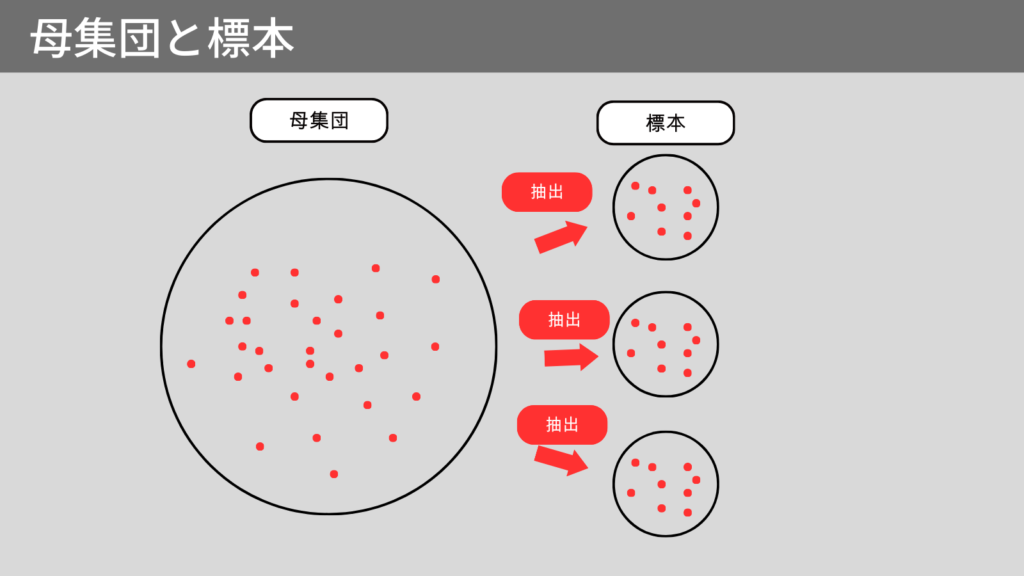
母集団と標本
母集団とは、調査対象となるデータ全体のことをいいます。
母集団に関する統計量を母数といいます。
母数の特性を知ることは難しいため一部を調査して母数の特性を推測します。
このときに母集団から一部を抽出したものを標本といいます。
また、標本に関する統計量を標本統計量といいます。
例えば、全国の成人の平均身長を調べたい場合、各データは以下の通りです。
- 母集団:全国の成人
- 母数:全国の成人の平均身長
- 標本:無作為に選ばれた成人100人
- 標本統計量:無作為に選ばれた成人100人の平均身長
このように、全国ひとりひとりの身長を調査するのは限界があるので、
標本及び標本統計量を用いて母数を推測します。
Pythonで標本を抽出する方法
母集団と標本を理解したら、Pythonで標本を抽出する方法を紹介します。
今回は、無作為に標本を抽出する方法として、以下の2つを紹介します。
- 母集団から無作為に標本を抽出
- データフレームから無作為に標本を抽出
母集団から無作為に標本を抽出する方法
母集団から無作為に標本を抽出するには、NumPyの以下メソッドを使用します。
今回はseabornのtipsのデータセットを使用します。
- np.random.choice(a, size=None, replace=True, p=None)
a: 配列size: 出力配列の形状。整数の場合は整数分の要素を持つ配列が返されるreplace: True=重複あり、False=重複なしp: 各要素が選択される確率
サンプルコードは以下の通りです。
import numpy as np
# 母集団の準備
data = np.arange(100)
# サンプルサイズ(標本のサイズ)
n = 50
sampled_data = np.random.choice(data, size=n, replace=False)
print(sampled_data)実行結果
[56 18 48 1 45 30 65 62 82 61 20 60 32 52 4 16 23 97 99 64 85 50 6 74
72 41 93 59 43 84 24 11 42 12 14 29 40 79 5 83 19 95 78 3 86 22 0 46
25 17]0から99のデータから無作為にデータを抽出しています。
データフレームから無作為に標本を抽出する方法
データフレームから無作為に標本を抽出するには、Pandasの以下メソッドを使用します。
- DataFrame.sample(n=None)
n: 抽出するサンプル数
他にも引数はありますが、今回使用する引数以外は省略します
サンプルコードは以下の通りです。
今回はseabornのデータセットtipsを使用します。
import pandas as pd
import seaborn as sns
# データフレームの準備
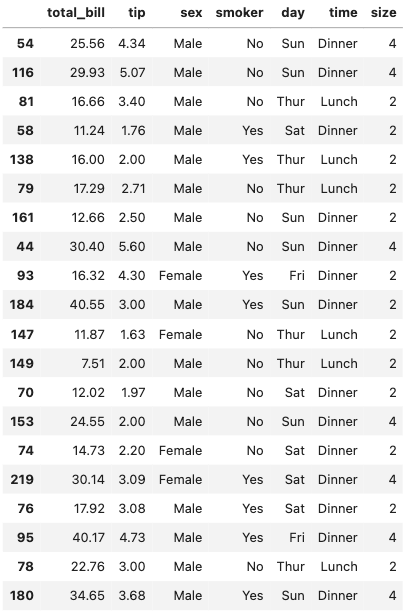
df = sns.load_dataset('tips')
# サンプルサイズ(標本のサイズ)
n = 20
# データフレームからサンプルサイズ分(20)を抽出
sampled_df = df.sample(n)
sampled_df実行結果
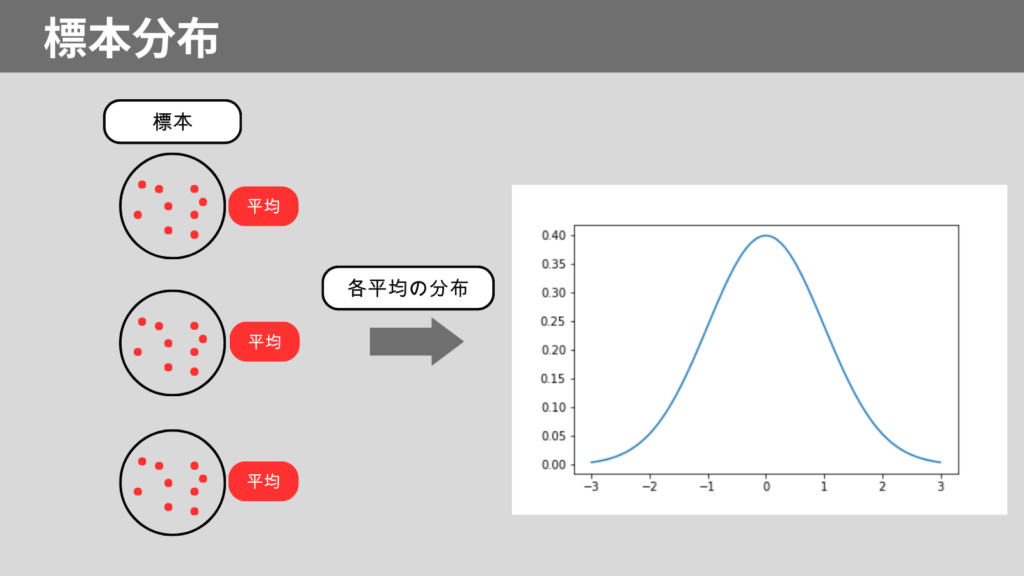
標本分布
標本分布とは標本ごとの統計量の分布のことです。
統計量は平均値が使用されることが多いです。
平均値の標本分布を標本平均の分布と呼ぶこともあります。
標本分布を用いて、母数を推定します。
中心極限定理
標本のサイズを十分大きくした場合、以下が成り立ちます。
これを中心極限定理といいます。
- 標本平均の分布の平均は母平均と同じになる
- 標本平均の分布の分散は母分散は\(\sigma^2 / n\)となる
この中心極限定理を利用し、母平均や、母分散を推定します。
Pythonで標本分布を作成する方法
Pythonで標本分布と、母平均、母分散を求めてみましょう。
先ほども使用したtipsのデータセットを使用します。
import pandas as pd
import seaborn as sns
# データフレームの準備
df = sns.load_dataset('tips')
# サンプルサイズ(標本のサイズ)
n = 50
# 標本平均を格納するリストの準備
sample_means = []
# サンプルサイズ分(n=50)標本を抽出し、これを1000回繰り返す
for i in range(1000):
# 標本の抽出
sampled_df = df.sample(n)
# 標本平均を算出
sample_mean = sampled_df['total_bill'].mean()
# リストに標本平均を追加
sample_means.append(sample_mean)
# 標本平均の標本分布を描画
sns.displot(sample_means)
# 標本平均の平均の出力
print("標本平均の平均", np.mean(sample_means))
# 母平均の出力
print("母平均", np.mean(df['total_bill']))
# 標本平均の分散の出力
print("標本平均の分散", np.var(sample_means))
# 母分散をnで割った値を出力
print("母分散/n", np.var(df['total_bill']) / n)実行結果
標本平均の平均 19.8203796
母平均 19.785942622950824
標本平均の分散 1.2575469823838399
母分散/n 1.5785626297702224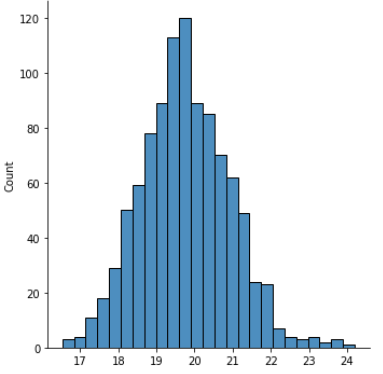
まとめ
今回は母集団と標本の関係からPythonで標本分布を作成する方法までを紹介しました。
母集団と標本の基本的な概念を理解しておくことで、
今後のデータ分析や解釈が正確になります。
ここまで読んでくださりありがとうございます。
参考
おすすめ教材
米国データサイエンティストが教える統計学超入門講座【Pythonで実践】

![]()
他のUdemyの講座が気になる方はこちら










