今回はt分布を使用し、平均値の区間推定方法を紹介します。
t分布とは
t分布(Student’s t-distribution)は標本サイズが小さいなどの場合に母平均を推定するときに使用します。
t分布の形状は自由度に依存します。この自由度が大きくなると、t分布は正規分布に近づきます。
自由度についてはあとで詳しく説明します。
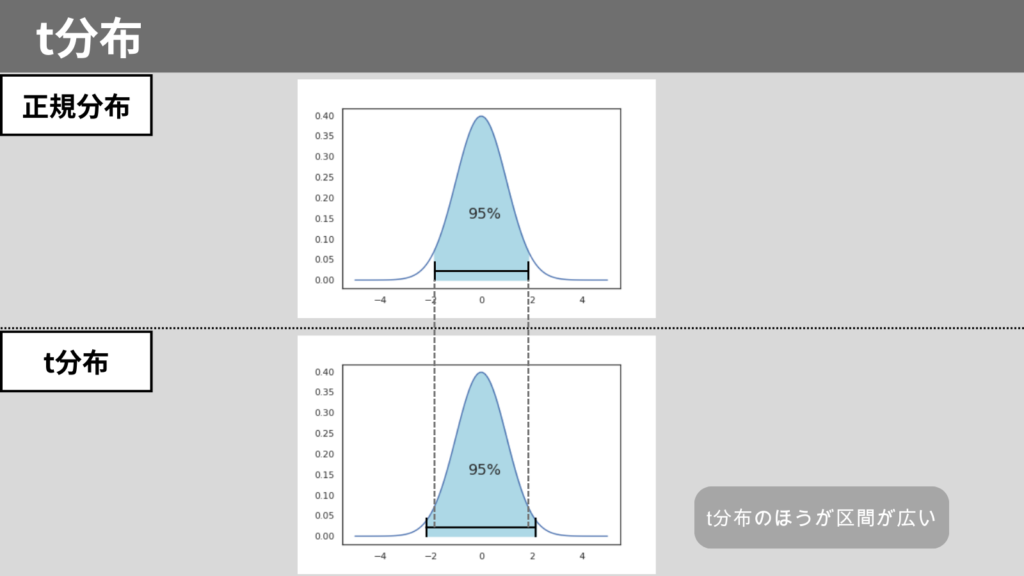
また、t分布は正規分布と比べて、裾野が広い特徴があります。
裾野が広いため、区間推定する場合は区間が広くなります。
t分布の自由度
t分布の特徴である自由度について説明していきます。
自由度は\(n-1\)で表されます。\(n\)は標本サイズです。
自由度が大きくなると、正規分布に近づきます。
イメージしやすいように自由度を変化させたときのグラフの形状の違いを以下に示します。
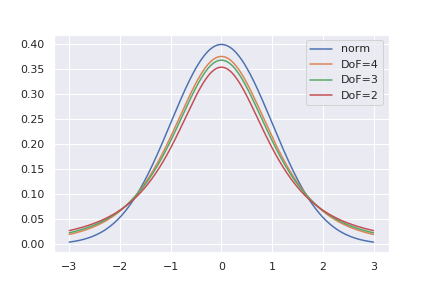
この図からも自由度を大きくすると、正規分布に近づくことがわかります。
Pythonでt分布を使用した平均値の区間推定
それではPythonでt分布を使用し、平均値の区間推定をしてみましょう。
t分布の区間推定するにはSciPyのstatsモジュールを使用します。
tがt分布を指し、intervalが区間推定を指しています。
stats.t.interval(alpha, loc, scale, df)
alpha:信頼区間(0.95=95%など)loc: 標本平均scale: 標準誤差df : 自由度
推定区間の下限値と上限値をタプルで返します。
tipsのデータセットを使用したサンプルコードは以下の通りです。
import pandas as pd
import seaborn as sns
from scipy import stats
alpha = 0.95 # 信頼区間
n = 10 # 標本サイズ
# データセットをロード
df = sns.load_dataset('tips')
# 標本の抽出
sample_df = df.sample(n)
# 標本平均
sample_mean = sample_df['total_bill'].mean()
# 不偏分散
sample_var = stats.tvar(sample_df['total_bill'])
# 標準誤差
std_error = np.sqrt(sample_var / n)
lower, upper = stats.t.interval(alpha, loc=sample_mean, scale=std_error, df=n-1)
print(f"total_billの95%信頼区間: ({lower:.2f}, {upper:.2f})")
# 母平均
population_mean = df['total_bill'].mean()
print(f"total_billの母平均: {population_mean:.2f}")実行結果
total_billの95%信頼区間: (11.20, 27.03)
total_billの母平均: 19.79これでtotal_billの平均値を95%の信頼区間で求めることができました。
母集団の平均が求めた区間に収まっていることがわかります。
まとめ
t分布を使用して平均値の区間推定する方法を紹介しました。
区間推定するときはt分布を使用する方法が一般的です。
また、自由度については統計学で頻出するのでぜひ理解していきましょう!
ここまで読んでくださりありがとうございます。
参考
おすすめ教材
米国データサイエンティストが教える統計学超入門講座【Pythonで実践】

他のUdemyの講座が気になる方はこちら










