今回は機械学習アルゴリズムの基本である、決定木について説明します。
決定木は、モデルが可視化されるので、ひとが解釈しやすいアルゴリズムです。
また、決定木をPythonを使用し、実装する方法を紹介していきます。
動画で詳しく学習したい方はこちらもおすすめ
決定木とは
決定木(decision tree)は、ツリー構造を用いて、データを分析する手法です。
ツリー構造とは、以下の図のように木の枝みたいな構造をいいます。
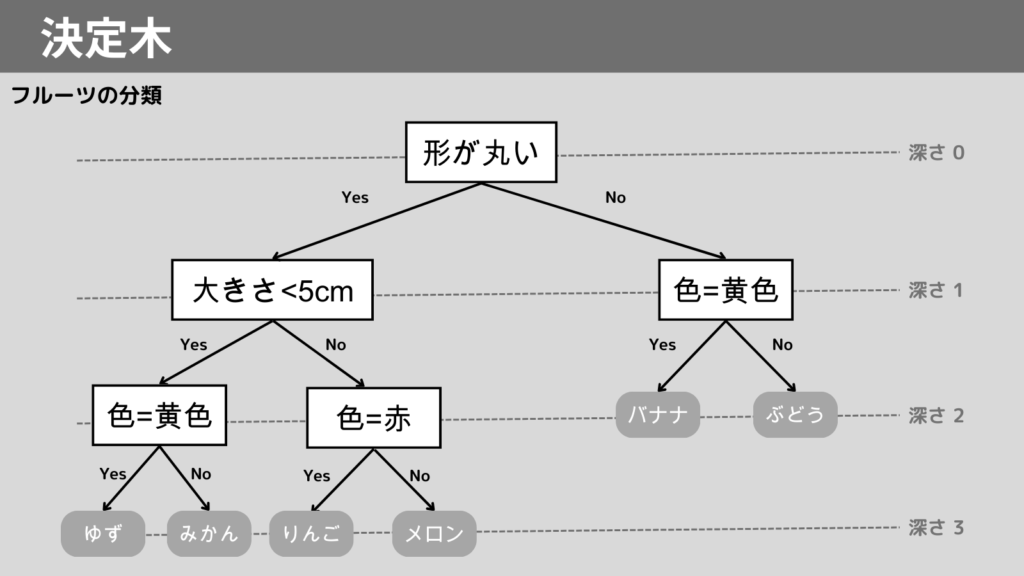
決定木は、教師あり学習の回帰および分類のどちらにも使用されます。
分類を行いたい場合の決定木を分類木、回帰を行いたい場合の決定木を回帰木といいます。
決定木のアルゴリズム
決定木の代表的なアルゴリズムであるCARTについて説明します。
CART(Classification and Regression Trees)は、分類と回帰の両方に使用できる決定木のアルゴリズムです。
ジニ不純度という指標を用いて分岐を行います。
ジニ不純度は、分類したデータにどれだけ不純なものを含んでいるかを表しています。
つまり、このジニ不純度が小さくなるように分類するのがCARTの特徴です。
ジニ不純度は以下式で表されます。
\[ G = 1 – \sum_{i=1}^n p_i^2 \]
決定木の特徴
決定木のメリット・デメリットは以下の通りです。
メリット
- 視覚的にわかりやすい
- 前処理が少ない
- 処理が高速
デメリット
- 過学習しやすい
- データの変化に弱い
Python実践 決定木
それでは、Pythonで使用し、決定木を実装してみましょう!
決定木をPythonで実装するには、scikit-learnライブラリを使用します。
決定木は以下方法で、モデルを作成します。
from sklearn.tree import DecisionTreeClassifier
モデル = DecisionTreeClassifier(max_depth=None, random_state=0)
モデル.fit(X, y)
サンプルコードで、決定木のモデルを作成してみましょう。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# サンプルデータの生成
X, y = make_blobs(n_samples=200, centers=3, random_state=6)
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 決定木モデルの作成と学習
model = DecisionTreeClassifier(max_depth=2, random_state=0)
model.fit(X_train, y_train)
# 境界線を描画するためのメッシュグリッドの作成
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# メッシュグリッドの各点でクラスを予測
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 境界線のプロット
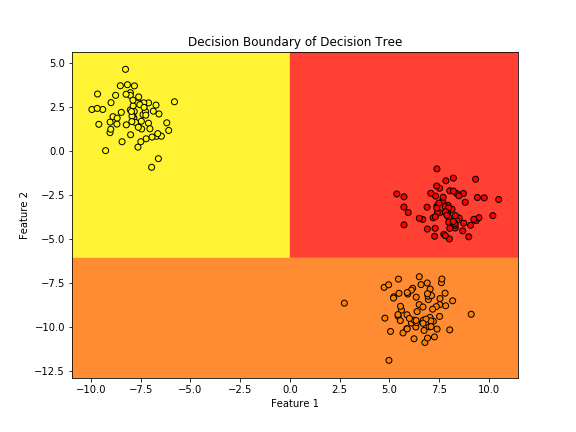
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap='autumn') # 境界線を塗り分け
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap='autumn') # データ点
plt.title("Decision Boundary of Decision Tree")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
実行結果
まとめ
機械学習の基本的なアルゴリズムである決定木について紹介しました。
決定木は、視覚的に人間にも理解しやすく、一方で、過学習が起こりやすいというデメリットもあるモデルです。
Pythonで決定木を実装するにはscikit-learnライブラリの以下を使用します。
from sklearn.tree import DecisionTreeClassifier
モデル = DecisionTreeClassifier(max_depth=None, random_state=0)
モデル.fit(X, y)
決定木は、別の機械学習アルゴリズムであるランダムフォレストの基本となる部分なので、ぜひ理解していきましょう!
ここまで読んでくださりありがとうございます。