今回は、ディープラーニングで頻出する用語である「バッチ処理」について紹介します。
バッチ処理の概要と、メリットなどを解説していきます。
また、Pythonでバッチ処理を実装する方法も合わせて説明します。
動画で詳しく学習したい方はこちらもおすすめ
目次
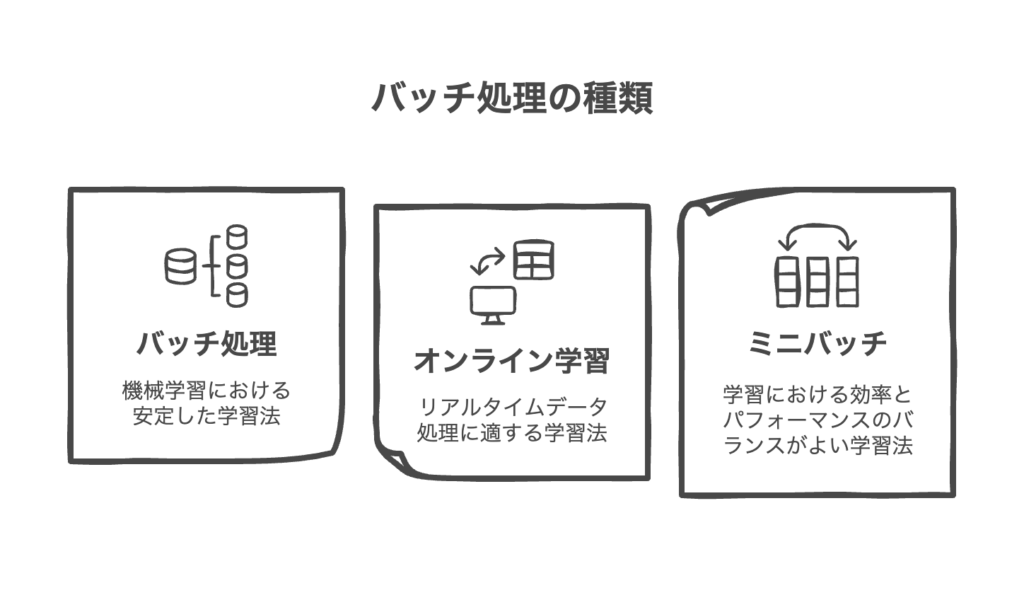
バッチ処理とは
バッチ処理とは、複数の処理をまとめて処理する方法をです。
ディープラーニングでは、一度に複数のデータ(バッチ)を使用して学習します。
一方、1件ずつデータを処理する方法を「オンライン学習」といいます。
また、バッチ処理とは別で「ミニバッチ」という処理もあります。
ミニバッチ処理とは、N個のデータから無作為にn個を抽出し、処理することをいいます。
それぞれの処理をまとめると以下の表の通りです。
| 学習方法 | 処理内容 |
|---|---|
| バッチ処理 | 全データを複数回に分けて処理 |
| オンライン学習 | 1件ずつ処理 |
| ミニバッチ処理 | 少数のサンプルを複数回に分けて処理 |
バッチサイズ
バッチサイズとは、1回の学習で処理するデータ数を意味します。
全体のデータ数が1000件のデータに対し、100件ずつ10回に分けてバッチ処理した場合、この100件がバッチサイズにあたります。
バッチサイズによる学習効果の違いは以下の通りです。
| バッチサイズ | 学習効果 |
|---|---|
| 小さい | メモリ使用量小、学習不安定 |
| 大きい | 学習安定、学習に時間を要する |
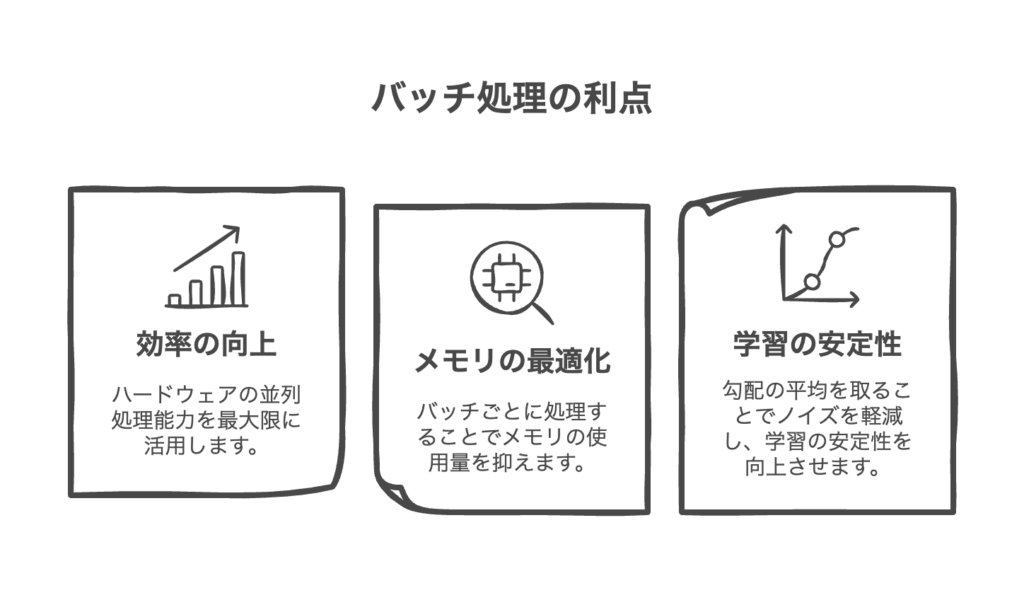
バッチ処理のメリット
バッチ処理のメリットは以下の通りです。
- 効率の向上
並列処理により、処理の高速化 - メモリの最適化
大きいデータを複数に分けて実行することにより、メモリの最適化可能 - 学習の安定性
1件ずつ処理するよりも、損失を小さくすることが可能
Python実践 バッチ処理
それでは、Pythonでバッチ処理を実装してみましょう!
バッチ処理のサンプルコードは以下の通りです。
import numpy as np
# ダミーデータ(100個のサンプル、1サンプルは10次元)
X = np.random.randn(100, 10)
y = np.random.randint(0, 2, size=(100,)) # 2クラス分類のラベル
# 初期パラメータ
W = np.random.randn(10) # 特徴量10次元
b = 0.0
lr = 0.01 # 学習率
# バッチサイズを設定
batch_size = 20
# シグモイド関数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# バッチ処理
for i in range(0, len(X), batch_size):
batch_X = X[i:i+batch_size]
batch_y = y[i:i+batch_size]
# 線形変換 + シグモイド(ロジスティック回帰)
z = np.dot(batch_X, W) + b
pred = sigmoid(z)
# 誤差と勾配
error = pred - batch_y
dW = np.dot(batch_X.T, error) / batch_size
db = np.mean(error)
# パラメータ更新
W -= lr * dW
b -= lr * db
print(f'Batch {i // batch_size + 1} updated.')
実行結果
Batch 1 updated.
Batch 2 updated.
Batch 3 updated.
Batch 4 updated.
Batch 5 updated.以下コードでバッチ処理を実現しています。
for i in range(0, len(X), batch_size):
batch_X = X[i:i+batch_size]
batch_y = y[i:i+batch_size]上記コードを実行すると、以下のような動きをします。バッチサイズが20とすると
- 1回目:
i=0→X[0:20] - 2回目:
i=20→X[20:40] - 3回目:
i=40→X[40:60]
まとめ
「バッチ処理」の概要とメリットを解説しました。
バッチ処理は、一度に複数のデータをまとめて処理する方法です。
バッチ処理を行うことで、学習が安定するなどのメリットがあります。
ここまで読んでくださりありがとうございます。