今回は、教師なし学習の主要な手法であるクラスタリングについて解説します。
クラスタリングの中でも特に、k-means クラスタリングを詳しく説明します。
また、k-meansクラスタリングをPythonで実装する方法も解説していきます。
動画で詳しく学習したい方はこちらもおすすめ
クラスタリングとは
データを自然なグループに分割するプロセスを指します。
教師なし学習のひとつであり、画像データを特徴量ごとに分類するときなど、様々な分野で活用されています。
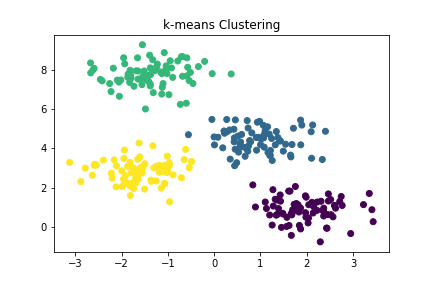
k-meansクラスタリング
k-meansとは
k-meansはデータをk個のクラスタに分類するアルゴリズムです。
クラスタ内のデータ間の距離が最小になるようにクラスタリングします。
以下は、クラスタ数kが3/4の場合を表しています。

kの決め方
クラスタ数kは、事前に決定しておく必要があります。
クラスタ数k を決定する方法はいくつかあります。ここではその中でも有名なエルボー法について説明します。
エルボー法とは、各kにおける誤差平方和(SSE)を計算し、計算結果をプロットすることで、適切なkを見つける手法です。
kとSSEの関係をプロットした図は以下の通りです。
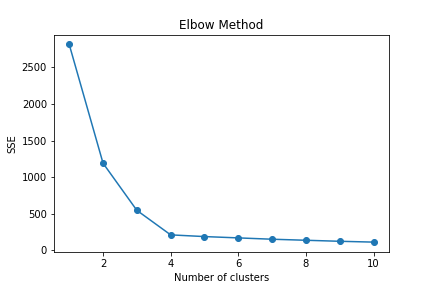
グラフが肘を曲げたような形をしていて、そのときの肘の位置に相当する箇所(k=4)が適切なkになります。
特徴
k-meamsクラスタリングのメリット・デメリットは以下の通りです。
メリット
- 計算が高速
- 解釈が容易
デメリット
- クラスタ数 k を事前に指定
- 球状のクラスタ以外の場合性能が低下するリスクあり
Python実践 k-meansクラスタリング
それではPythonを使用し、k-meansクラスタリングを実装してみましょう!
scikit-learnライブラリを使用します。
使い方は以下の通りです。
from sklearn.cluster import KMeans
モデル = KMeans(n_clusters=4, random_state=0)
モデル.fit(X)
引数のn_clustersでクラスタ数(k)を指定します。
サンプルコードは以下の通りです。
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# データの生成
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# k-meansクラスタリング
kmeans = KMeans(n_clusters=4, random_state=0)
kmeans.fit(X)
# クラスタ中心とラベルの取得
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# 可視化
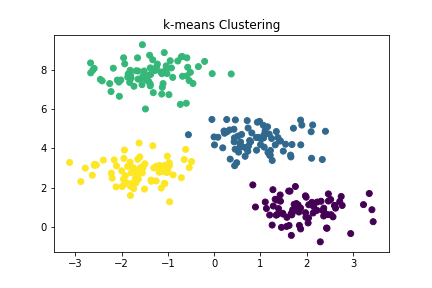
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title("k-means Clustering")
plt.show()
実行結果
まとめ
クラスタリングの中でも一般的なk-meansクラスタリングについて解説しました。
k-meansクラスタリングとは、データをk個のクラスタに分類する手法であり、計算と解釈が容易という特徴を持つアルゴリズムです。
k-meansクラスタリングをPythonで実装する方法は以下の通りです。
from sklearn.cluster import KMeans
モデル = KMeans(n_clusters=4, random_state=0)
モデル.fit(X)
ここまで読んでくださりありがとうございます。