今回は、クラスタリングを評価する指標について紹介します。
また、実際にPythonを使用し、クラスタリングを評価する方法を解説します。
動画で詳しく学習したい方はこちらもおすすめ
クラスタリングを評価する指標
クラスタリングを評価する指標は大きく2つに分類されます。
- 外部評価指数
正解ラベルありのデータに使用 - 内部評価指数
正解ラベルなしのデータに使用
今回は、正解ラベルありのデータに使用する「内部評価指数」について詳しく紹介していきます。
内部評価指標
内部評価指標には、いくつか指標があります。その中でも主要なものであるシルエット分析について紹介します。
シルエット分析
シルエット分析は、各データがどの程度適切にクラスタリングされているかを評価する手法です。
計算したシルエット係数をプロットし、クラスタリングを評価します。
シルエット係数
シルエット係数は、各データが適切にクラスタリングされているかを数値で評価できます。
-1から1の範囲で表され、1に近いほど適切にクラスタリングされていることを示します。
シルエット係数は以下の過程で計算できます。
- 凝集度 \( a_i \)を計算 同一クラスタ内の他のデータとの平均距離
- 乖離度 \(b_i\)を計算 最も近い別のクラスタ内の全データとの平均距離
- シルエット係数 \(s_i\)を計算 凝集度と乖離度の差をどちらかの大きい方で割る
シルエット係数の計算は以下の通りです。
\[ s_i = \frac{b_i – a_i}{\max\{b_i, a_i\}} \]
\(\max\) {\(A, B\)}: AとBの大きい方のどちらかを選択
シルエット係数のプロット
クラスタごとのシルエット係数をプロットすることで、視覚的にクラスタリングを評価可能です。
以下は、実際のシルエット係数をプロットした図です。
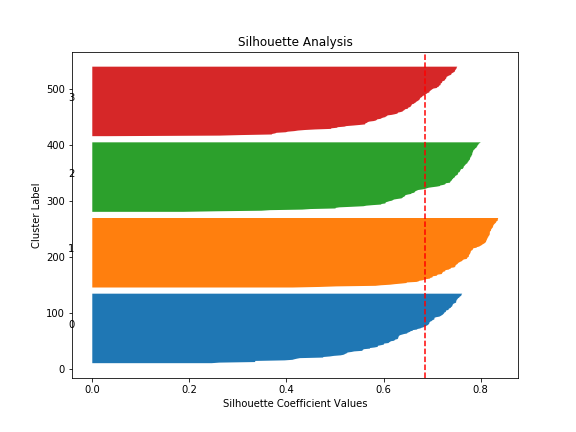
バー幅: 幅が狭い箇所は、クラスタ内のデータが一貫せず、誤ったクラスタリングを含む可能性があることを指す赤い破線: 各クラスタのシルエット係数の平均。データ全体のクラスラリングを評価する際に使用
Python実践 シルエット係数
それでは、実際にPythonでシルエット係数を実装してみましょう!
sklearnのmetrics モジュールを使用します。
from sklearn.metrics import silhouette_samples, silhouette_score
シルエット係数 = silhouette_samples(X, クラスタリング結果)
シルエット係数の平均 = silhouette_score(X, クラスタリング結果)
k-meansでクラスタリングした結果に対し、シルエット係数を計算し、プロットしてみます。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
# データの生成
X, _ = make_blobs(n_samples=500, centers=4, cluster_std=0.60, random_state=0)
# クラスタリングの実行
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters)
labels = kmeans.fit_predict(X)
# シルエット分析
silhouette_avg = silhouette_score(X, labels)
sample_silhouette_values = silhouette_samples(X, labels)
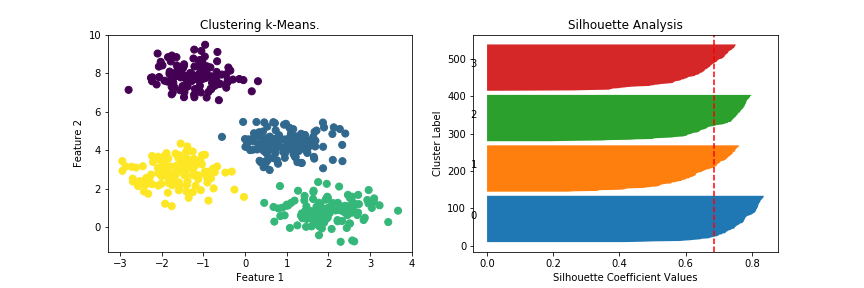
# k-Meansによるクラスタリング
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
axes[0].set_title("Clustering k-Means.")
axes[0].set_xlabel("Feature 1")
axes[0].set_ylabel("Feature 2")
# シルエットプロットの作成
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
axes[1].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values)
axes[1].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10 # 次のクラスタのために間隔を空ける
axes[1].set_title('Silhouette Analysis')
axes[1].set_xlabel('Silhouette Coefficient Values')
axes[1].set_ylabel('Cluster Label')
axes[1].axvline(x=silhouette_avg, color="red", linestyle="--")
plt.show()実行結果
まとめ
正解ラベルなしのクラスタリングに対する評価方法である「内部評価指標」を紹介しました。
「内部評価指標」の中でも最も有名はシルエット係数に焦点を当てて説明しました。
シルエット係数は、各データが適切にクラスタリングされているかを数値で評価します。
また、シルエット係数は各クラスタごとにプロットすることで、視覚的に適切にクラスタリングされているかを確認可能です。
ここまで読んでくださりありがとうございます。