今回は、モデルの性能を適切に評価するために重要な交差検証(クロスバリデーション)を紹介します。
主要な交差検証の手法について、Pythonのコードと合わせて説明してきます。
動画で詳しく学習したい方はこちらもおすすめ
交差検証とは
交差検証(Cross-Validation)は、モデルの性能を評価するための手法です。
データを分割し、それらで訓練と評価を繰り返すことでモデルの性能の正確に評価します。
交差検証をすることで、過学習を防ぐことができます。
特定のデータに依存せず、あらゆるデータ(未知のデータ)に対応できるモデルかを評価できます。
交差検証の種類
交差検証の中にもさまざまな手法が存在します。
代表的な手法は以下の通りです。
- k分割交差検証
- 層化k分割交差検証
- リーブワンアウト交差検証(LOOCV)
- シャッフル分割交差検証
それぞれについて解説していきます。
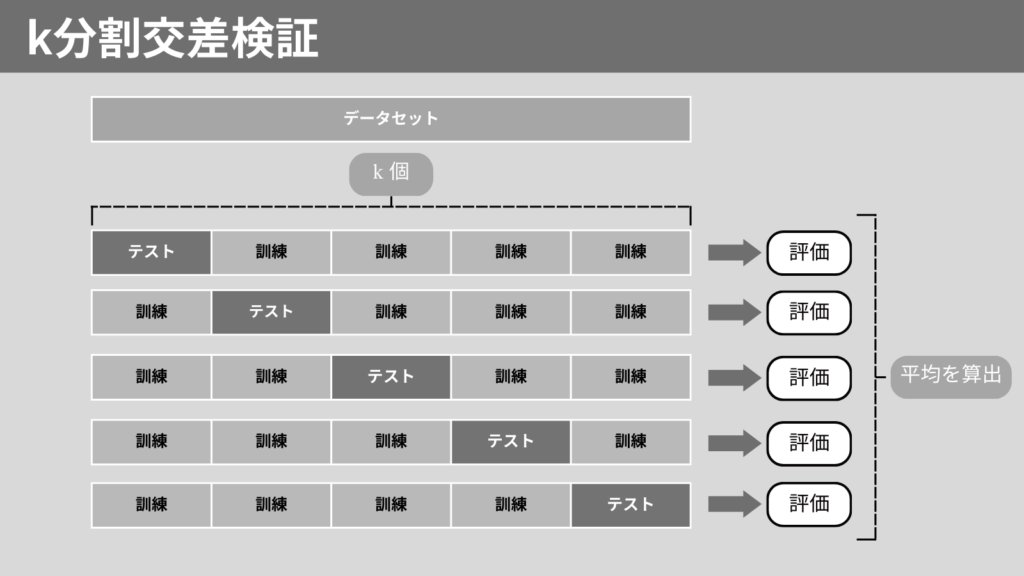
k分割交差検証
k分割交差検証(k-Fold Cross-Validation)は、データセットをk個に等分割します。
このk個のうち1つをテストデータとし、残りを訓練データにします。
これをk回繰り返します。最終的にすべての学習の平均化します。
データセットをテストデータとするため、偏りがなくモデルを評価できます。
Python実践 k分割交差検証
それでは、k分割交差検証をPythonで実装してみましょう!
sklearnモジュールのmodel_selectionを使用します。
from sklearn.model_selection import KFold, cross_val_score
# k分割交差検証
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# モデルの性能を評価
scores = cross_val_score(モデル, X, y, cv=kf)
n_splits: 分割数(kの値)shuffl: データをシャッフルするかどうか(デフォルトはFalse)random_state: シャッフルを有効にした場合の乱数シード
k分割交差検証を使用し、ランダムフォレストのモデルを評価するサンプルコードは以下の通りです。
from sklearn.model_selection import KFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# モデルの定義
model = RandomForestClassifier(random_state=42)
# k-分割交差検証
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kf)
print(f"各フォールドの正確度: {scores}")
print(f"平均正確度: {scores.mean()}")
実行結果
各フォールドの正確度: [1. 0.96666667 0.93333333 0.93333333 0.96666667]
平均正確度: 0.9600000000000002層化k分割交差検証
層化k分割交差検証(Stratified k-Fold Cross-Validation)は、データグループの分布が均等になるようにデータを分割します。
データグループによる偏りがなくなるため、k分割交差検証よりも偏りなくモデルを評価できます。
特に分類問題に対するモデルの評価に使用されます。

Python実践 層化k分割交差検証
それでは、層化k分割交差検証をPythonで実装してみましょう!
sklearnモジュールのmodel_selectionを使用します。
from sklearn.model_selection import StratifiedKFold, cross_val_score
# 層化k分割交差検証
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# モデルの性能を評価
scores = cross_val_score(モデル, X, y, cv=skf)
n_splits: 分割数(kの値)shuffl: データをシャッフルするかどうか(デフォルトはFalse)random_state: シャッフルを有効にした場合の乱数シード
層化k分割交差検証を使用し、ランダムフォレストのモデルを評価するサンプルコードは以下の通りです。
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# モデルの定義
model = RandomForestClassifier(random_state=42)
# 層化k分割交差検証
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=skf)
print(f"Stratified k-Foldの平均正確度: {scores.mean()}")
実行結果
Stratified k-Foldの平均正確度: 0.9466666666666667リーブワンアウト交差検証 LOOCV
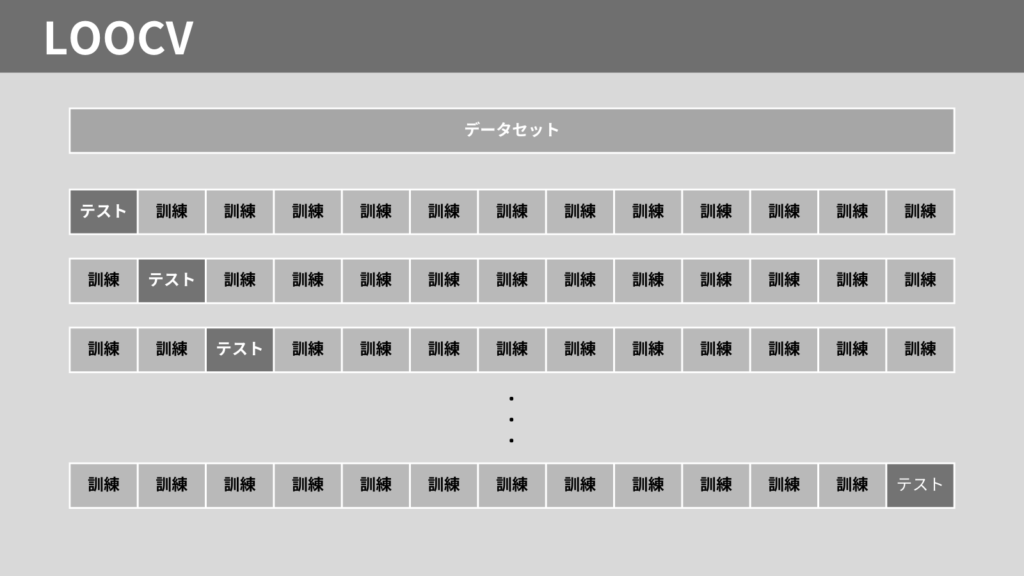
リーブワンアウト交差検証(Leave-One-Out Cross-Validation, LOOCV)は、データひとつひとつをテストデータにする手法です。
1つのデータをテストデータとし、残りを訓練データとします。これをすべてのデータに対し、く返します。
データひとつひとつをテストデータとするため、精度が高い評価が可能ですが、計算コストが高くなってしまいます。
Python実践 LOOCV
それでは、LOOCVをPythonで実装してみましょう!
sklearnモジュールのmodel_selectionを使用します。
from sklearn.model_selection import LeaveOneOut, cross_val_score
# LOOCV
loo = LeaveOneOut()
# モデルの性能を評価
scores = cross_val_score(model, X, y, cv=loo)
LOOCVを使用し、ランダムフォレストのモデルを評価するサンプルコードは以下の通りです。
from sklearn.model_selection import LeaveOneOut, cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# モデルの定義
model = RandomForestClassifier(random_state=42)
# LOOCV
loo = LeaveOneOut()
scores = cross_val_score(model, X, y, cv=loo)
print(f"LOOCVの平均正確度: {scores.mean()}")
実行結果
LOOCVの平均正確度: 0.9533333333333334シャッフル分割交差検証
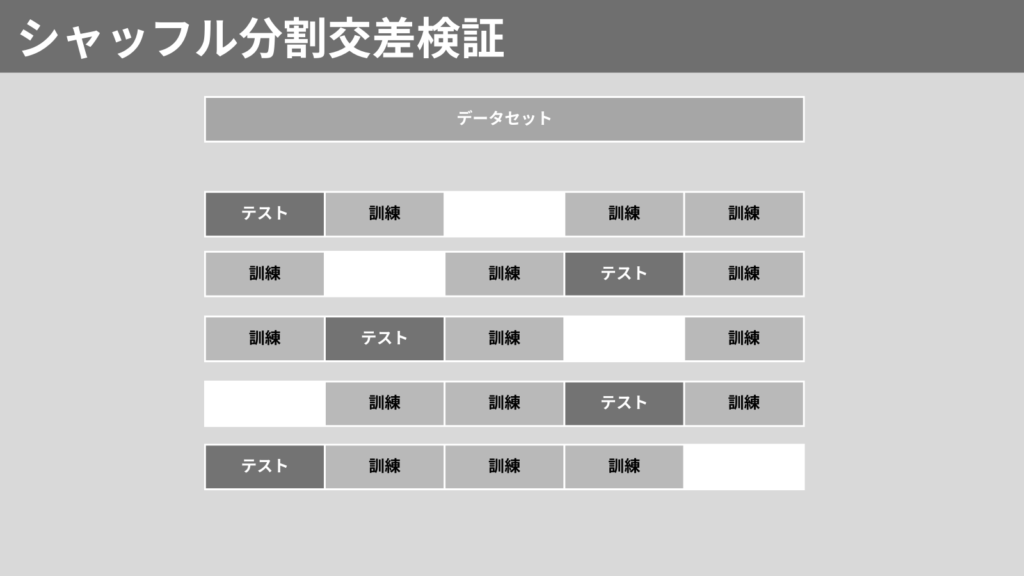
シャッフル分割交差検証(Shuffle Split Cross-Validation)は、データをランダムにシャッフルし、指定した割合でデータを訓練データとテストデータに分割する手法です。
これを複数回繰り返すことで、精度が高い評価が可能です。
Python実践 シャッフル分割交差検証
それでは、シャッフル分割交差検証をPythonで実装してみましょう!
sklearnモジュールのmodel_selectionを使用します。
from sklearn.model_selection import ShuffleSplit, cross_val_score
# シャッフル分割交差検証
ss = ShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
# モデルの性能を評価
scores = cross_val_score(model, X, y, cv=ss)
n_splits: 分割数(交差検証の回数)test_size: テストデータの割合(0〜1の範囲)random_state: 乱数シード
シャッフル分割交差検証を使用し、ランダムフォレストのモデルを評価するサンプルコードは以下の通りです。
from sklearn.model_selection import ShuffleSplit, cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# モデルの定義
model = RandomForestClassifier(random_state=42)
# シャッフル分割交差検証
ss = ShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
scores = cross_val_score(model, X, y, cv=ss)
print(f"Shuffle Splitの平均正確度: {scores.mean()}")
実行結果
Shuffle Splitの平均正確度: 0.9600000000000002まとめ
交差検証の以下の手法に対して、Pythonのコードと合わせて紹介しました。
- k分割交差検証
- 層化k分割交差検証
- リーブワンアウト交差検証(LOOCV)
- シャッフル分割交差検証
sklearnのmodel_selection モジュールを使用すれば、容易に実装できることがわかったと思います。
ここまで読んでくださりありがとうございます。