今回は、dropna()を使用し、DataFrameの欠損値(NaN)を削除する方法を紹介します。
欠損値とは
データの中にある、不足しているデータ、または値のことをいいます。
このような欠損値を含むデータがある場合、欠損値を削除する処理が必要になります。
欠損値が残ったままデータ分析を続けると、品質の悪い分析結果になってしまいます。
dropna()について
pandasの欠損値は、dropna()関数を使い、削除します。
dropna()関数の使い方は以下の通りです。
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)axis: 削除する方向を指定。0 は行、1は列を削除。デフォルトは0
how:anyまたはall。デフォルトはanyanyはひとつでも値がNaNの場合に行または列を削除allはすべての値がNaNの場合に行または列を削除
thresh: NaNの許容値。NaNでない数が指定した値未満の行または列を削除subset: 行または列を指定。指定した行または列にNaNを含んでいた場合に削除inplace:TrueまたはFalse。デフォルトはFalseTrueはもとのデータフレームを更新するFalseはもとのデータフレームは更新せず、欠損値を削除したデータフレームを返す
動きがイメージしづらいhow, thresh, subsetについて詳しく紹介します。
また、以下のデータを使って紹介していきます!
import pandas as pd
# データフレームを作成
data = {'A': [0, 1, None, 3, 4],
'B': [0, 1, None, None, None],
'C': [0, 1, None, None, None],
'D': [0, None, None, None, 4],
'E': [0, 1, None, 3, 4]}
df = pd.DataFrame(data)
df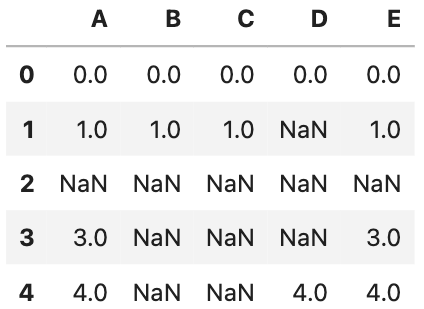
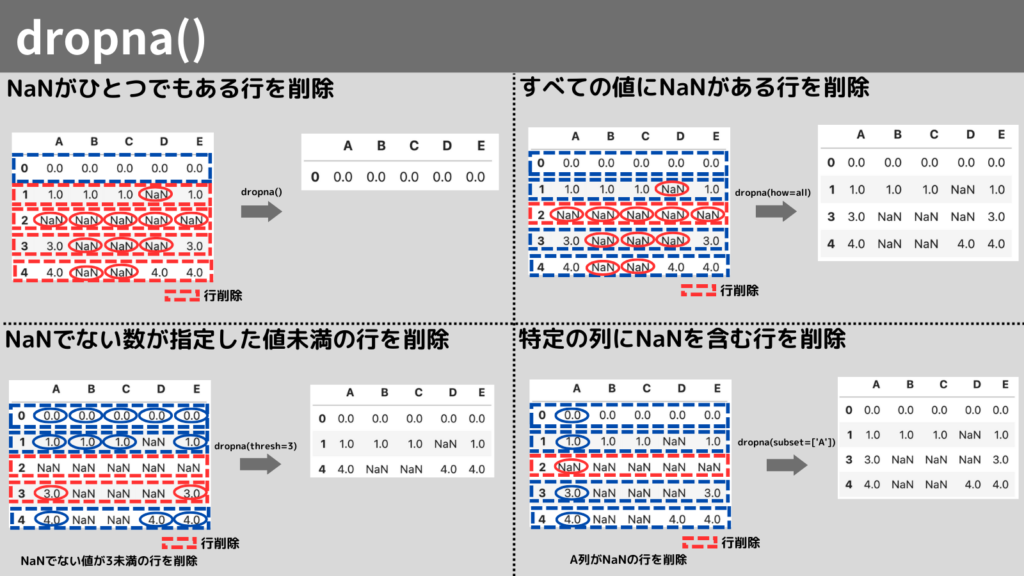
ひとつでも値がNaNの場合に行または列を削除: how=any
ひとつでもNaNを含んでいる場合に行を削除する方法は、
dropna()の引数にhow=anyを指定します。
ただし、デフォルトでhowにはanyが指定されているので、
実際の使い方は以下の通り、引数には何も指定する必要がありません。
df.dropna()実行した結果は以下です。

NaNをひとつも含んでいない、index0以外の行が削除されました。
すべての値がNaNの場合に行または列を削除: how=all
すべての値がNaNの行を削除する方法は、
dropna()の引数にhow=allを指定します。
実際の引数を指定する方法は以下の通りです。
df.dropna(how='all')実行した結果は以下です。
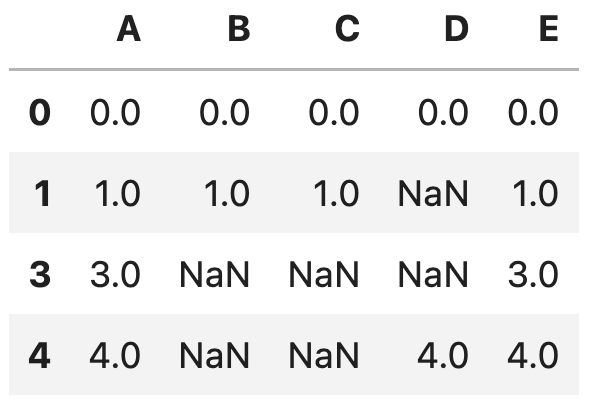
すべての値がNaNである、index2の行が削除されました。
NaNでない数が指定した値未満の行を削除:thresh
NaNでない数が、指定した値未満のNaNを含む行を削除する方法は、
dropna()の引数にthreshを指定します。
実際の引数を指定する方法は以下の通りです。
df.dropna(thresh=3)実行した結果は以下です。
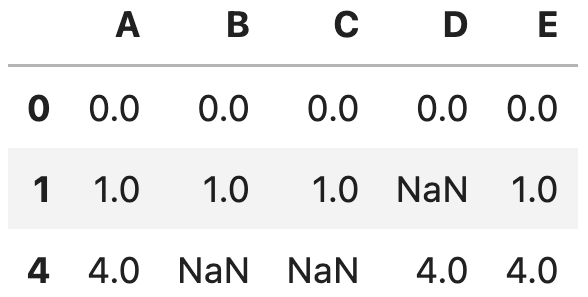
NaNでない値の数が3未満である、indexが2, 3の行が削除されました。
特定の列にNaNを含む行を削除:subset
特定の列にNaNを含んでいる行を削除する方法は、
dropna()の引数にsubsetを指定します。
df.dropna(subset=['A'])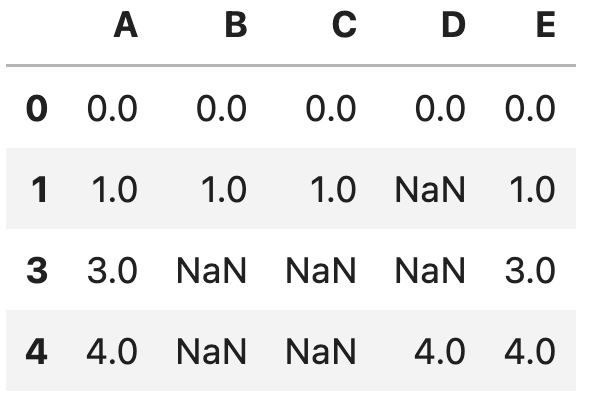
列AにNaNを含んでいる、indexが2の行が削除されました。
まとめ
dropna()を使用し、NaNを含む行または列を削除する方法を紹介しました!
すべて理解しなくても、こういう使い方もできるんだってことを知るだけでいいと思います!
参考
おすすめ教材
米国データサイエンティストがやさしく教えるデータサイエンスのためのPython講座