今回は、機械学習の基礎的なアルゴリズムである、ロジスティック回帰について解説します。
また、ロジスティック回帰をPythonを使用した実装方法も合わせて紹介します。
動画で詳しく学習したい方はこちらもおすすめ
ロジスティック回帰とは
ロジスティック回帰(Logistic Regression)は、2値に分類する統計手法です。
2値に分類とは、「はい/いいえ」「合格/不合格」など答えが2つしかないものをどちらかに分類することです。
例えば、以下のような場面で使用します。
- メールが「スパム」か「スパムでない」かを判定
- 顧客が製品を「購入する」か「購入しない」かを予測
数学的仕組み
ロジスティック回帰についての理解を深めるために、数学的な仕組みを簡単に説明します。
ロジスティック回帰で、2値(0か1か)を分類するときは、シグモイド関数を使用しています。
シグモイド関数の式は以下で表されます。
\[ \sigma = \frac{1}{1 + e^{-x}} \]
図で表すと以下です。
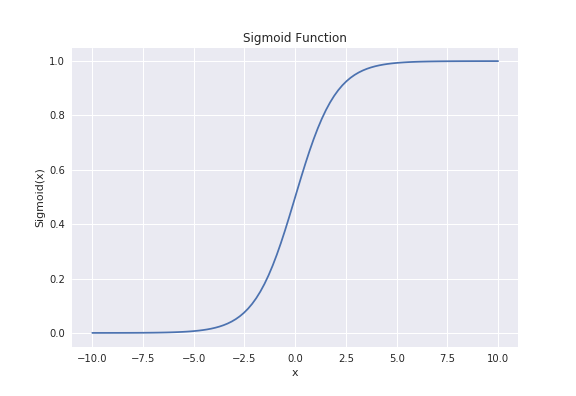
シグモイド関数を通すことで、0〜1の値を得ることができます。
そのため、シグモイド関数の出力で、分析対象のデータが0か1かを分類するのです。
特徴
ロジスティック回帰のメリット・デメリットは以下の通りです。
メリット
- シンプルで解釈しやすい
- 学習が高速
デメリット
- 非線形な関係を表現できない
- 複雑な関係を捉えられない
Python実践 ロジスティック回帰
Pythonを使用し、ロジスティック回帰を実装してみましょう!
ロジスティック回帰をPythonで実装するには、scikit-learnライブラリを使用します。scikit-learnについて詳しく知りたい方はこちら
ロジスティック回帰のモデルは、以下を使用します。
モデル = LogisticRegression()
モデル.fit(X, y)
ロジスティック回帰モデルを実装するサンプルコードは以下の通りです。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# データを訓練データとテストデータに分割
X, y = make_blobs(random_state=0, n_features=2, centers=2, cluster_std=1, n_samples=200)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# モデルの作成
model = LogisticRegression()
model.fit(X_train, y_train)
# 予測結果とスコアを出力
pred = model.predict(X_test)
score = model.score(X_test, y_test)
print(f"正解値: {y_test}")
print(f"予測結果: {pred}")
print(f"スコア: {score}")
# 予測結果を散布図で描画
plt.scatter(X_test[:, 0], X_test[:, 1], c=pred)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
実行結果
正解値: [1 1 0 0 0 1 0 0 0 0 1 1 1 1 0 0 1 1 1 1 0 0 1 1 1 1 1 0 0 0 1 0 1 0 0 0 0
0 0 0 0 1 1 0 0 0 1 1 1 0]
予測結果: [1 1 0 0 0 1 0 0 0 0 1 1 1 1 0 1 1 1 1 1 0 0 1 1 1 1 1 0 0 0 1 0 1 0 0 0 0
0 0 0 0 1 1 0 1 0 1 1 1 0]
スコア: 0.96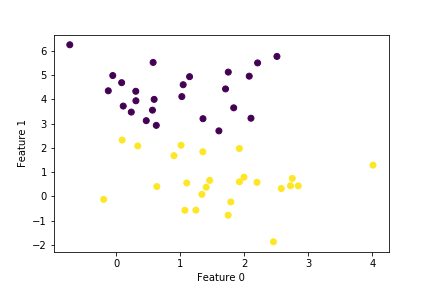
scikit-learnを使用し、簡単にロジスティック回帰モデルを実装できることがわかると思います。
まとめ
今回は、機械学習アルゴリズムの基本であるロジスティック回帰について、紹介しました。
ロジスティック回帰は、データを分類するケースで使用します。
Pythonでロジスティック回帰モデルを実装するときは、以下のように使用します。
モデル = LogisticRegression()
モデル.fit(X, y)
Pythonを使用すると、簡単に実装できるので、ぜひみなさんも他のデータを使用し、試してみてください。
ここまで読んでくださりありがとうございます。