今回は、機械学習の教師あり学習を解説します。
動画で詳しく学習したい方はこちらもおすすめ
教師あり学習とは
教師あり学習とは、正解ラベルのついたデータを用いて、モデルを訓練される手法です。
教師あり学習で使用するアルゴリズム
機械学習には、様々なアルゴリズムが存在します。
アルゴリズムとは、データを予測や分類をしてくれる手法のことです。
アルゴリズムによって、予測、分類方法が異なります。
そのため、機械学習を実施する際は、最適なアルゴリズムを選択する必要があります。
機械学習アルゴリズムには、以下2種類があります。
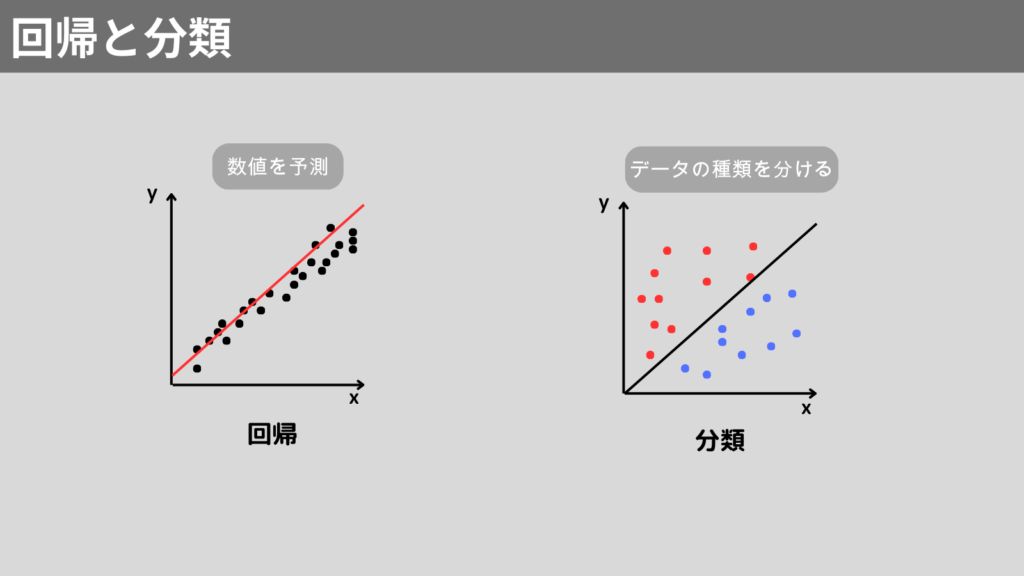
- 回帰(Regression) 連続的な数値を予測
- 分類(Classification) データの種類を予測
それでは、具体的な教師あり学習のアルゴリズムを紹介します。
1. 回帰: 線形回帰
線形回帰は、連続的なデータに対し、予測するためのアルゴリズムです。
住宅の価格予測や売上予測などに用いられます。
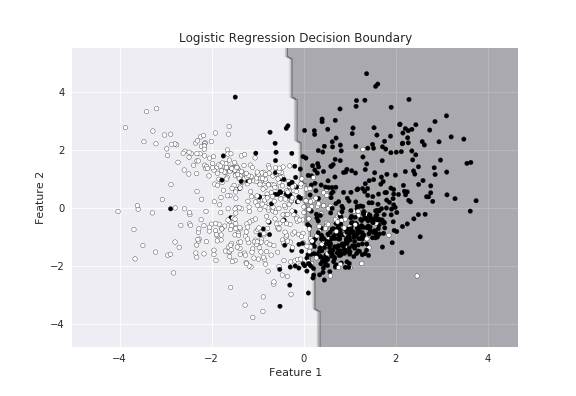
2. 分類: ロジスティク回帰
ロジスティク回帰は、2値のデータを分類するアルゴリズムです。
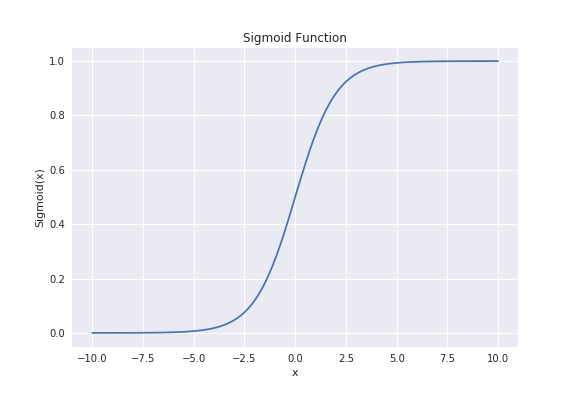
シグモイド関数で、出力を0から1に制限することで、データの分類をしています。
3. 分類: SVM(サポートベクターマシン)
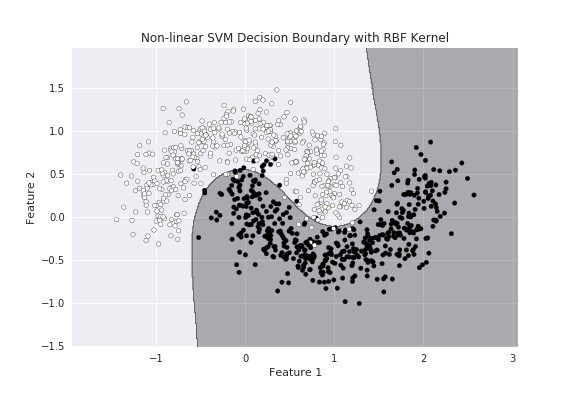
SVM(サポートベクタマシン)は、データを線形または非線形に分類するアルゴリズムです。
データ間のマージンを最大に確保する境界線を引きます。
画像認識、異常検知などに用いられます。
4. 分類: 決定木
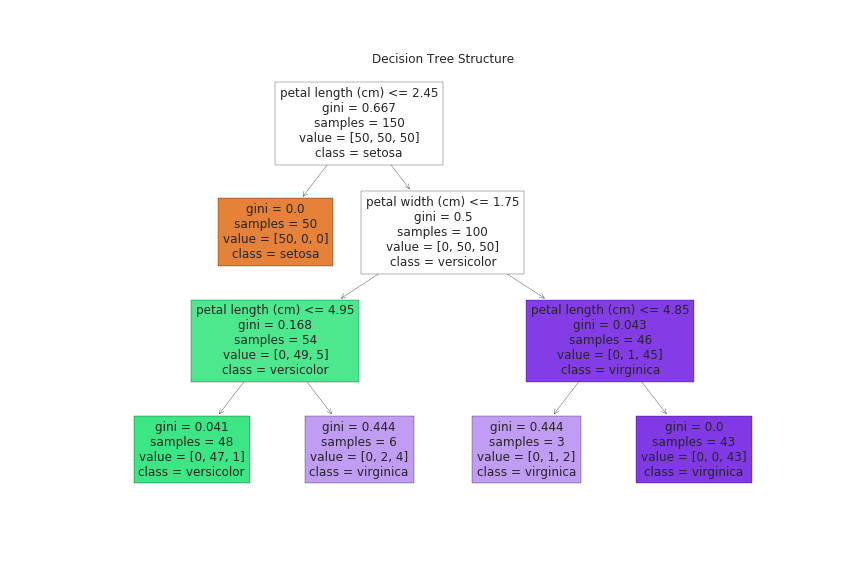
決定木は、データをツリー構造で、質問をしながら分類するアルゴリズムです。
分類が単純なので、人間にも理解しやすいアルゴリズムになっています。
データを分類するための質問を繰り返すので、過学習しやすい傾向にあります。
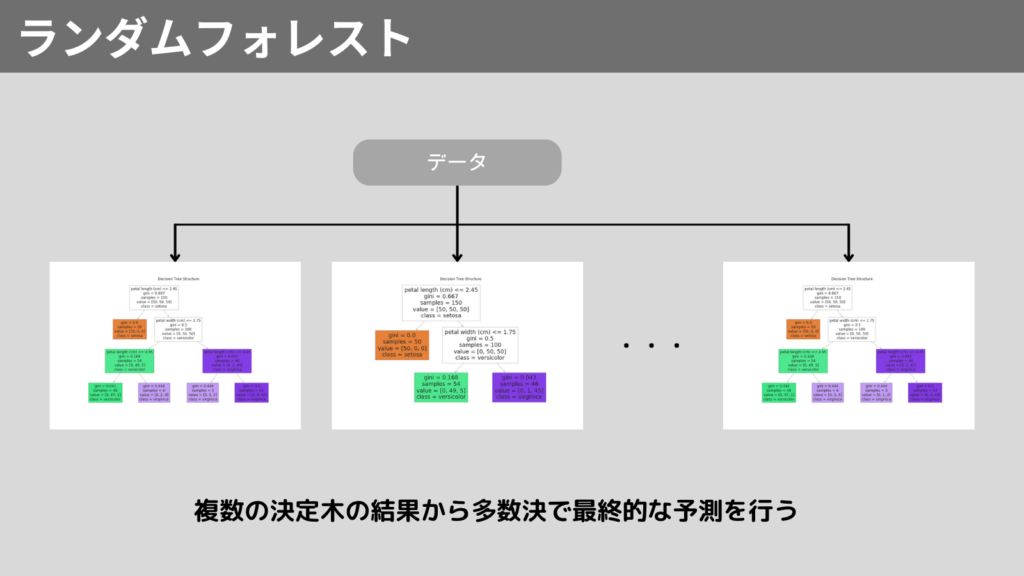
5. 分類: ランダムフォレスト
ランダムフォレストは、決定木を改良したアルゴリズムです。
複数の決定木を作成し、その結果を多数決で予測します。
予測精度の高いアルゴリズムになっています。
6. 分類: k近傍法(k-NN)
k近傍法は、近くのデータは同じ分類であるということに基づいてデータを分類するアルゴリズムです。
近くのk個のデータの特徴からどの分類に当てはまるかを調べます。
パターン認識などに用いられます。
Python実践 教師あり学習
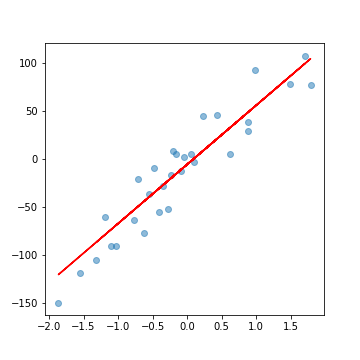
Pythonを用いて、機械学習アルゴリズムのひとつである、線形回帰を実装してみます。
scikit-learnを使用します。scikit-learnについて詳しく知りたい方はこちら
# 必要なライブラリのインポート
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
X, y = make_regression(random_state=3, n_features=1, noise=20, n_samples=30)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# モデルの作成
lr = LinearRegression()
# 訓練データでモデルの学習
lr.fit(X_train, y_train)
# モデルの評価
print("Test score: {:.2f}".format(lr.score(X_test, y_test)))
# グラフを表示
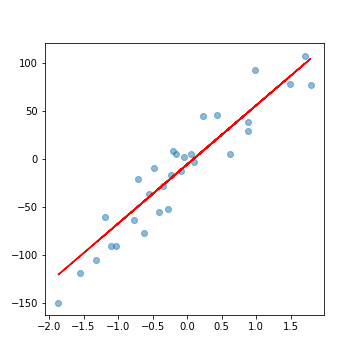
plt.figure(figsize=(5, 5))
plt.scatter(X, y, alpha=0.5)
# 直線の描画
plt.plot(X, lr.predict(X), color='r')
実行結果
まとめ
今回は、機械学習の教師あり学習の基本的なアルゴリズムを紹介しました。
機械学習において、どのアルゴリズム(モデル)を選択するかが、重要になります。
なので、それぞれのアルゴリズムの特徴を理解していただければと思います。
ここまで読んでくださりありがとうございます。