今回は、機械学習アルゴリズムのなかでも高い予測精度をほこることから人気のある勾配ブースティング決定木を解説します。
勾配ブースティング決定木のアルゴリズム、特徴、およびPythonを使用した実装方法を紹介します。
動画で詳しく学習したい方はこちらもおすすめ
勾配ブースティング決定木とは
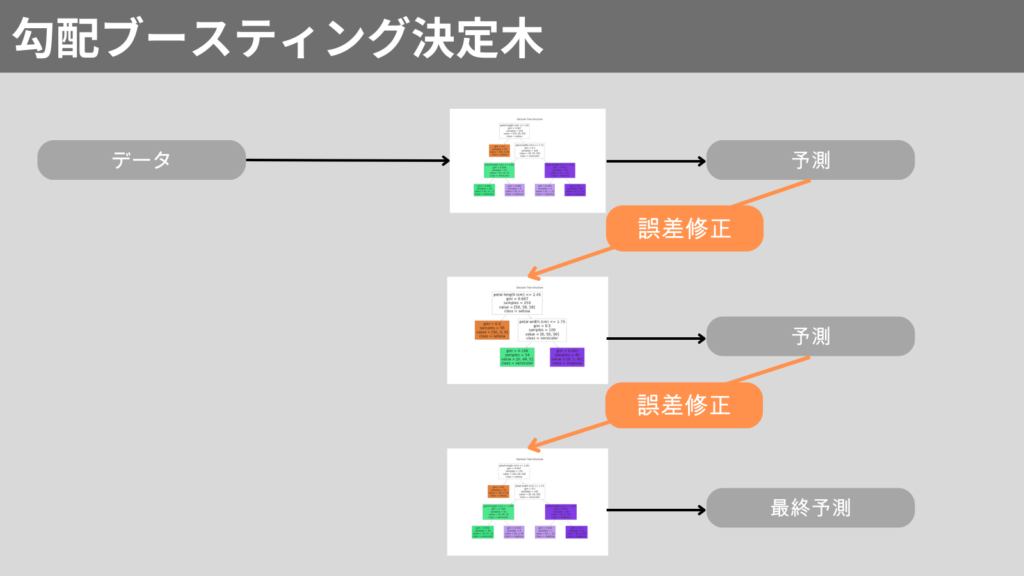
勾配ブースティング決定木(Gradient Boosting Decision Tree、GBDT)は、決定木をアンサンブル学習のブースティングを使用し、強力なモデルを構築するアルゴリズムです。
ブースティングのときに誤差を最小化するために勾配降下法を使用します。
勾配降下法とは
勾配降下法とは、損失関数の最小値を見つけるために使用されます。
パラメータを損失が減るように調整することで、最小値を求めます。
ブースティングとは
ブースティングとは、弱い学習器(決定木など)を組み合わせて、強い学習器作るアンサンブル学習です。
弱い学習器で予測した結果の誤差を修正しながら、より高い精度のモデルを構築します。
この誤差に注目することがブースティングの特徴です。
勾配ブースティング決定木の特徴
勾配ブースティング決定木のメリット・デメリットは以下の通りです。
メリット
- 高精度なモデル
予測精度の低い決定木を勾配ブースティングにより高精度化 - 汎用性が高い
複雑な前処理を必要としない
デメリット
- 学習に時間がかかる
逐次決定木を作成するので、モデル構築に時間がかかる - 過学習を起こしやすい
同じデータを何度も使用するので、過学習が起こりやすい
勾配ブースティング決定木のライブラリ
勾配ブースティング決定木にはいくつかのライブラリがあります。
ここでは主なライブラリを3つ紹介します。
- XGBoost
勾配ブースティング決定木を効率的に実装したライブラリで、最も広く利用されている - LightGBM
Microsoftが開発したライブラリで、大規模なデータセットに適している - CatBoost
Yandexが開発したライブラリで、カテゴリデータに適している
Python実践 勾配ブースティング決定木
それでは、Pythonを使用し、勾配ブースティング決定木を実装してみましょう!
勾配ブースティング決定木をPythonで実装するには、scikit-learnライブラリを使用します。
勾配ブースティング決定木は以下方法で、モデルを作成します。
from sklearn.ensemble import GradientBoostingClassifier
モデル = GradientBoostingClassifier()
モデル.fit(X_train, y_train)
サンプルコードで勾配ブースティング決定木を実装してみます。
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
import matplotlib.pyplot as plt
# サンプルデータの生成
X, y = make_blobs(n_samples=200, centers=3, random_state=6)
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# GBDTモデルの生成と学習
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 境界線を描画するためのメッシュグリッドの作成
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# メッシュグリッドの各点でクラスを予測
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 境界線のプロット
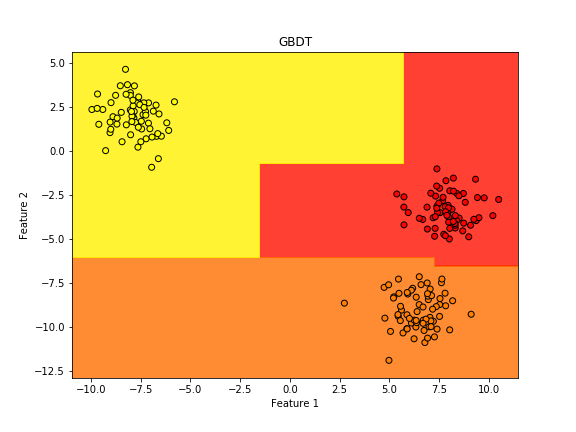
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap='autumn') # 境界線を塗り分け
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap='autumn') # データ点
plt.title("GBDT")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
実行結果
まとめ
勾配ブースティング決定木は、予測精度の低い決定木を複数組み合わせて,予測精度を向上させたアルゴリズムです。
誤差を補正しながら決定木を組み合わせていきます。
ライブラリも充実しているので、とても扱いやすいアルゴリズムになっています。
Pythonで勾配ブースティングを実装する方法は以下の通りです。
from sklearn.ensemble import GradientBoostingClassifier
モデル = GradientBoostingClassifier()
モデル.fit(X_train, y_train)
ここまで読んでくださりありがとうございます。