今回は、機械学習の基本である、汎化と過学習について解説します。
汎化と過学習は、選択したモデルが機能しているか、評価するために使用します。
動画で詳しく学習したい方はこちらもおすすめ
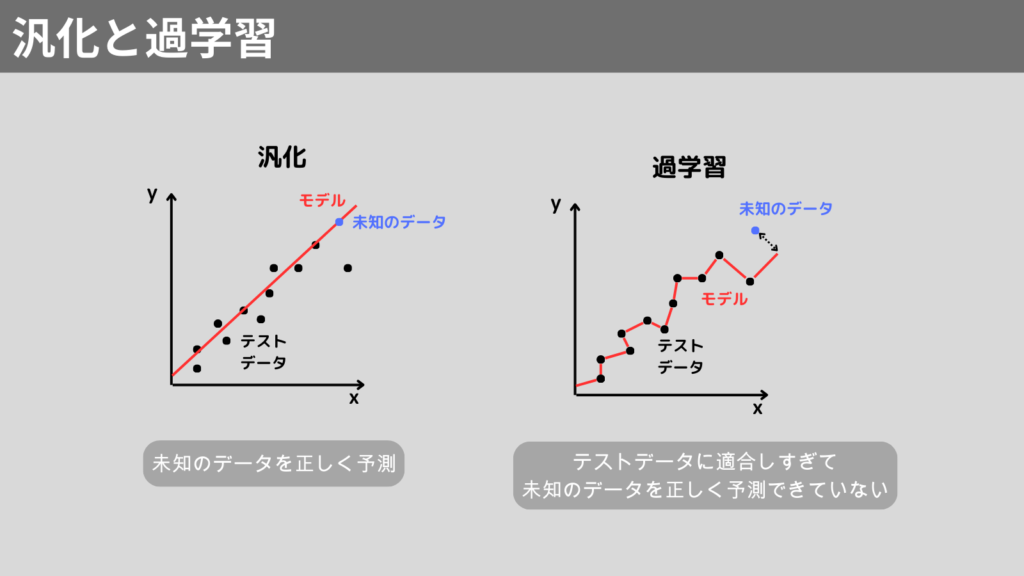
汎化と過学習
汎化は、モデルが訓練データだけでなく、未知のデータにも正確に予測を行う能力を指します。
一方、過学習は、モデルが訓練データに適応しすぎて、未知のデータに対する予測の精度が低下する現象です。
このように機械学習を実施するときは、過学習を防ぎ、汎化を高めるために、適切な学習をする必要があります。
過学習の対策
では、過学習はどのように防げはよいのでしょうか。
ここからは、過学習の対策方法について説明します。
過学習の主な対策方法は以下の通りです。
- データ量を確保
- シンプルなモデルを選択
- データの偏りをなくす
データ量を確保
データ量を十分に確保することで、過学習を防ぐことができます。
データ量を増やすと、その分さまざまなパターンのデータを学習できるようになります。
シンプルなモデルを選択
モデルを複雑にしてしまうと、ノイズや偶然発生しているパターンに引きずられてしまいます。
そのため、モデルは複雑にすればよいのではなく、シンプルに汎用性の高いモデルにする必要があります。
データの偏りをなくす
データの偏りをなくすことも過学習を防ぐためには重要です。
データに偏りがあると、そのデータパターンに結果が依存してしまいます。
データは偏りなく、適切に訓練データとテストデータに分割することが求められます。
Python実践
Pythonを用いて、実際の機械学習のプロセスにおける過学習を対策する様子を表現してみます。
線形回帰で求められる予測値よりを過学習を防ぎ汎化性能を高めるために、他のモデル(リッジ回帰)を選択した例を紹介します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.datasets import load_diabetes
# データセットの読み込み
X, y = load_diabetes(return_X_y=True)
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルの学習と評価
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_pred_linear = lin_reg.predict(X_test)
# テストデータに対するスコアを格納
score_linear = lin_reg.score(X_test, y_test)
# リッジ回帰モデルの学習と評価(正則化パラメータ alpha = 0.1)
ridge_reg = Ridge(alpha=0.1)
ridge_reg.fit(X_train, y_train)
pred_ridge = ridge_reg.predict(X_test)
# テストデータに対するスコアを格納
score_ridge = ridge_reg.score(X_test, y_test)
# 結果の表示
print(f"線形回帰: {score_linear: .3f}")
print(f"リッジ回帰: {score_ridge: .3f}")
実行結果
線形回帰: 0.453
リッジ回帰: 0.461わずかですが、線形回帰よりも、リッジ回帰のほうがテストデータに対するスコアが良いです。
(値が1に近いほど、スコアが良い)
このようにモデルを変更するだけでも、過学習を防ぎ、汎化性能を高めることが可能です。
まとめ
今回は機械学習の汎化と過学習について解説しました。
機械学習では、汎化性能を高め、過学習を防ぐことが重要です。
このことを重点において機械学習を進めていっていただければ、と思います。
ここまで読んでくださりありがとうございます。