機械学習(ディープラーニング)の分野では、過学習が問題になることが多々あります。
今回は、過学習を抑制する手法を紹介していきます。
また、過学習を抑制する手法をPythonで実装する方法を紹介します。
動画で詳しく学習したい方はこちらもおすすめ
過学習とは

過学習は、訓練データに適応しすぎてしまい、テストデータに対応できていない現象のことをいいます。
ディープラーニングでは、テストデータ(未知のデータ)に対し、予測精度が高いモデルが望まれます。
そのため、テストデータに対応できなくなってしまう過学習を抑制することが重要になります。
過学習の主な要因
過学習の主な要因は以下の通りです。
| 原因 | 説明 |
|---|---|
| モデルが複雑 | ニューラルネットワークの層やパラメータが多いと、訓練データに細部まで適応してしまう |
| データ量が少ない | 訓練データが少ないと、限られたデータに適応してしまう |
| エポックが多い | 学習させすぎると、過剰に適応してしまう |
過学習を抑制する手法
過学習を抑制する手法はいくつかありますが、代表的な手法は以下です。
- Weight decay(荷重減衰)
- Dropout(ドロップアウト)
- Early Stopping(早期終了)
それぞれの手法を詳しく説明していきます。
Weight decay(荷重減衰)
Weight decayとは、学習中に重みが大きくならないように小さくする手法です。
重みが大きいと、訓練データに過剰に適応する傾向があります。
そのため、意図的に重みを小さくし、汎用的なニューラルネットワークにするのです。
以下の式で表されます。
$$ L'(\theta) = L(\theta) + \frac{\lambda}{2} \|\theta\|^2 $$
\( L(\theta) \): 損失関数 \( \lambda \): ハイパーパラメータ(Weight decayの強さ) \( |\theta|^2 \): 重みベクトルの2乗
Dropout(ドロップアウト)
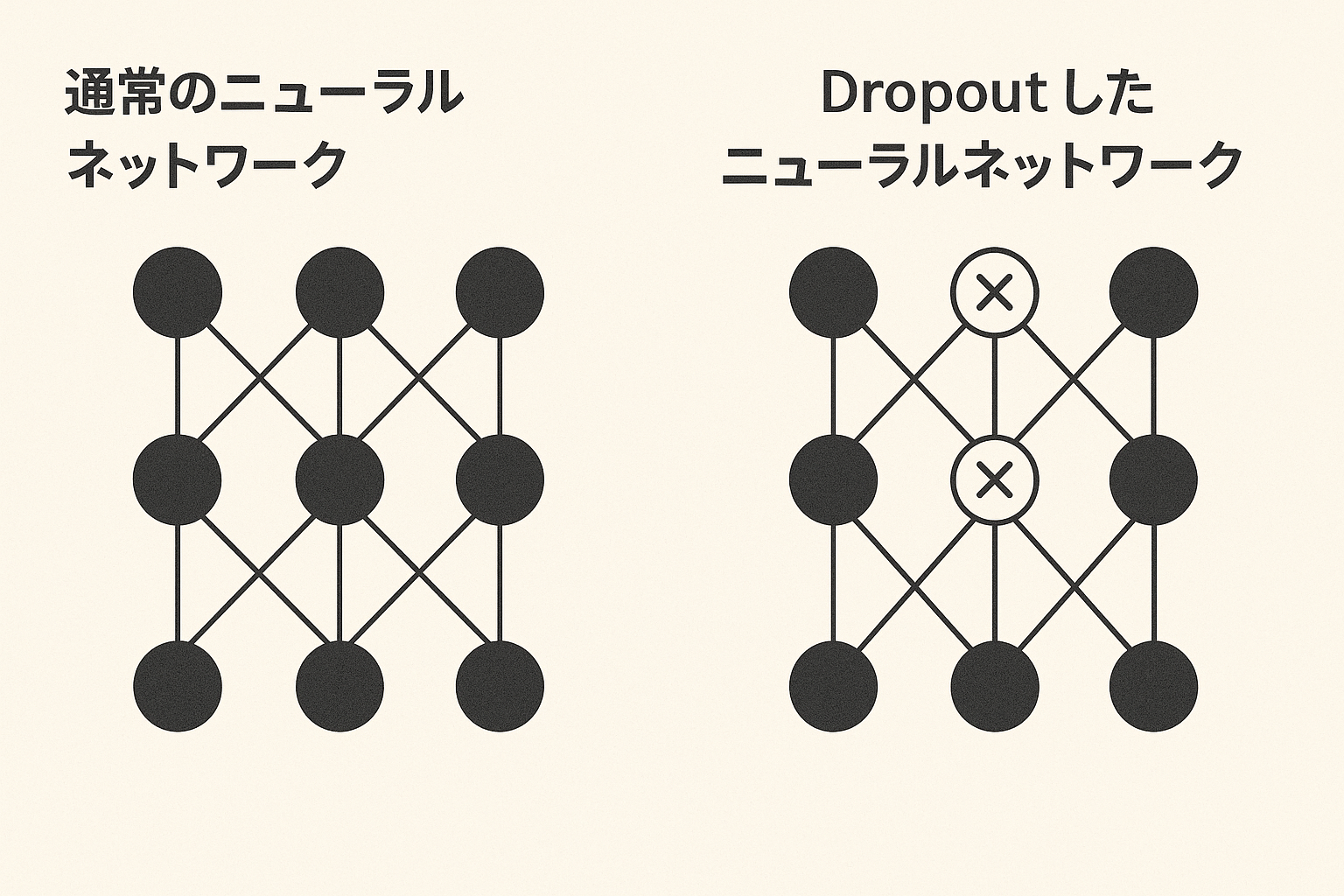
Dropoutは、学習中に一部のニューロンをランダムに無効化する手法です。
一部のニューロンを無効化することで、ニューラルネットワークが特定のニューロンに過剰に適応することを防ぎます。
Dropoutのイメージ図は以下です。
Early Stopping(早期終了)
Early Stoppingは、検証データに対し、損失が悪化し始めたタイミングで学習を途中で打ち切る手法です。
学習するにつれて訓練データへの適応が進み、ある時点から訓練データに過剰に適応し始めることがあります。
そこで、訓練データに過剰に適応する前に学習を止めることで、過学習を防ぐのがEarly Stoppingの仕組みです。
Python実践 過学習を抑制する手法
これまで紹介した過学習を抑制する手法のうち「Weight decay」と「Dropout」についてPythonで実装する方法を紹介します。
事前準備として、活性化関数と損失関数を実装します。
import numpy as np
# シグモイド関数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# ソフトマックス関数(多クラス分類用)
def softmax(x):
x = x - np.max(x, axis=1, keepdims=True)
exp_x = np.exp(x)
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
# 交差エントロピー損失
def cross_entropy_loss(y, t):
return -np.sum(t * np.log(y + 1e-8)) / y.shape[0]Python実践 Weight decay
PythonでWeight decayを実装する方法を紹介します。
サンプルコードは以下の通りです。
class WeightDecay:
def __init__(self, input_size, hidden_size, output_size, weight_decay_lambda=0.01):
self.weight_decay_lambda = weight_decay_lambda
self.params = {
'W1': np.random.randn(input_size, hidden_size) * 0.01,
'b1': np.zeros(hidden_size),
'W2': np.random.randn(hidden_size, output_size) * 0.01,
'b2': np.zeros(output_size)
}
def forward(self, x):
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
self.z1 = np.dot(x, W1) + b1
self.a1 = sigmoid(self.z1)
self.z2 = np.dot(self.a1, W2) + b2
self.y = softmax(self.z2)
return self.y
def loss(self, x, t):
y = self.forward(x)
loss = cross_entropy_loss(y, t)
# weight decayの実装
loss += 0.5 * self.weight_decay_lambda * (np.sum(self.params['W1']**2) + np.sum(self.params['W2']**2))
return loss関数loss の損失関数を計算している箇所で、変数lossに対し、Weight decayを実装しています。
Python実践 Dropout
PythonでDropoutを実装する方法を紹介します。
サンプルコードは以下の通りです。
class Dropout:
def __init__(self, input_size, hidden_size, output_size, dropout_ratio=0.5, train_flg=True):
self.dropout_ratio = dropout_ratio
self.train_flg = train_flg
self.params = {
'W1': np.random.randn(input_size, hidden_size) * 0.01,
'b1': np.zeros(hidden_size),
'W2': np.random.randn(hidden_size, output_size) * 0.01,
'b2': np.zeros(output_size)
}
def forward(self, x):
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
self.z1 = np.dot(x, W1) + b1
self.a1 = sigmoid(self.z1)
# Dropoutの実装
if self.train_flg:
self.mask = np.random.rand(*self.a1.shape) > self.dropout_ratio
self.a1 *= self.mask
else:
self.a1 *= (1.0 - self.dropout_ratio) # 推論時スケーリング
self.z2 = np.dot(self.a1, W2) + b2
self.y = softmax(self.z2)
return self.y
def loss(self, x, t):
y = self.forward(x)
return cross_entropy_loss(y, t)
関数forwardで、ランダムで生成したもののうちdropout_ratioより大きい要素だけをTrueとしたmaskを用いることでDropoutを実現しています。
まとめ
ディープラーニングの過学習とはなにか、過学習を抑制する手法を紹介しました。
代表的な過学習の抑制手法である「Weight decay」、「Dropout」について、Pythonで実装する方法も合わせて解説しました。
ディープラーニングの分野で過学習は避けなければいけない問題です。
ぜひ今回紹介した過学習を抑制する手法だけでも覚えていただければと思います。
ここまで読んでくださりありがとうございます。