今回は、機械学習でモデルを構築する前に実施する前処理について紹介します。
モデルの予測精度を最大限高めるために、適切な前処理を実施する必要があります。
前処理の具体的な手法をPythonを使用し、解説していきます。
動画で詳しく学習したい方はこちらもおすすめ
機械学習の前処理とは
前処理とは、モデルを学習させる前に、学習しやすいようにデータを加工することです。
前処理をすることで、精度、処理速度を向上させることが可能です。
機械学習の前処理には以下があります。
- データクリーニング: 欠損値、外れ値の処理
- 特徴量エンコーディング: カテゴリデータを数値化
- 特徴量スケーリング: 特徴量間のスケールをあわせる
それぞれについて以降で詳しく説明していきます。
データクリーニング
データクリーニングとは、機械学習モデルが効率よく処理できるようにデータセットを整えることです。
データクリーニングのひとつとして、欠損値や外れ値の処理などがあります。
ここでは、欠損値の処理について詳しく説明したいと思います。
欠損値の処理
欠損値(NaN)の処理方法は以下があります。
- 削除: 欠損値を含む行や列を削除
- 補完: 欠損値を平均値や最頻値で補完
Python実践 欠損値の削除
Pythonを使用し、欠損値を削除する方法を紹介します。
pandasライブラリを用いることで、簡単に欠損値を簡単に削除可能です。
サンプルコードは以下の通りです。
import pandas as pd
# サンプルデータ
data = {
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': ['a', 'b', 'c', 'd']
}
# データフレームの作成
df = pd.DataFrame(data)
# 欠損値の削除
df.dropna()実行結果(削除前と後を表示)
NaN削除前
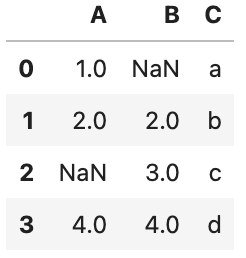
NaN削除後
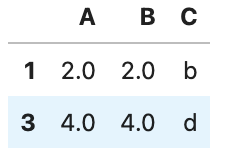
削除前後を見比べると、NaNを含んでいた行を削除されていることがわかると思います。
特徴量エンコーディング
特徴量エンコーディングとは、機械学習モデルが理解できるように、非数値データ(赤、青、緑など)を数値データ変換するプロセスです。
コンピュータは、赤が何かなどは理解できないので、0, 1などの数値に変換しておく必要があります。
特徴量エンコーディングの手法として、主に以下があります。
- Labelエンコーディング
- One-Hotエンコーディング
それぞれについては以降で説明します。
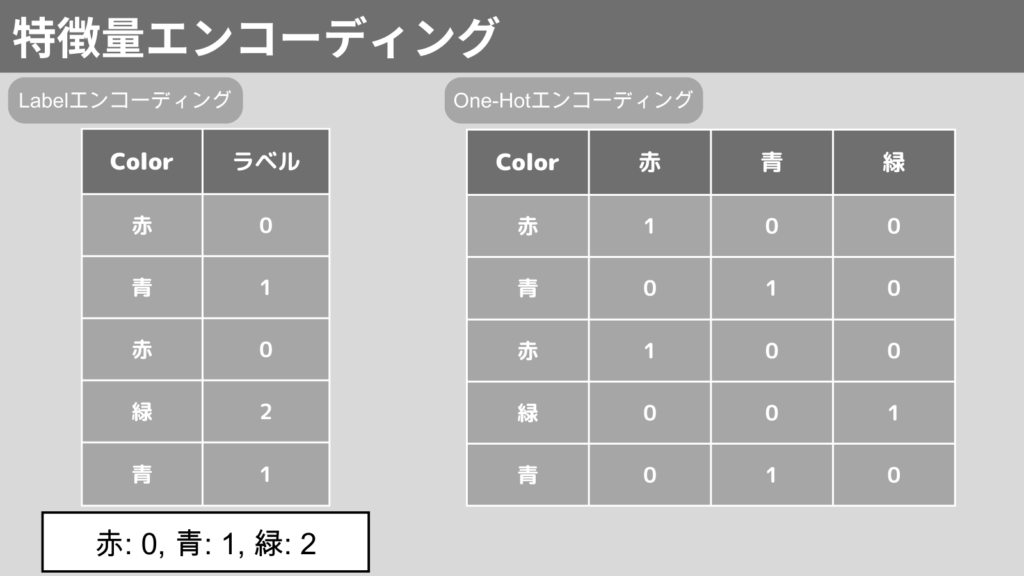
Labelエンコーディング
Labelエンコーディングとは、カテゴリデータを数値ラベル(0, 1, 2,…)に変換するプロセスです。
One-Hotエンコーディング
One-Hotエンコーディングとは、カテゴリごとに列を作成し、対応するカテゴリであれば”1”、対応がなければ”0”を設定します。
以下はLabel/One-Hotエンコーディングを具体的な例で表したものです。
Python実践 Labelエンコーディング
Pythonを使用し、Labelエンコーディングを実装する方法を紹介します。
scikit-learnライブラリを使用します。
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# サンプルデータ
data = {'Color': ['Red', 'Blue', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# ラベルエンコーディング
label_encoder = LabelEncoder()
df['Color_Label'] = label_encoder.fit_transform(df['Color'])
df実行結果
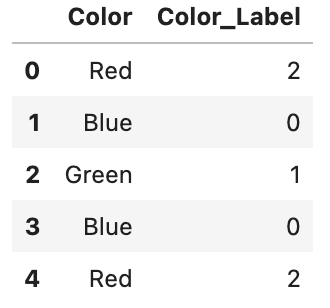
Colorの列に対し、以下ラベルがColor_Labelに振られていることがわかります。
Red: 2, Blue: 0, Green: 1
Python 実践 One-Hotエンコーディング
Pythonを使用し、One-Hotエンコーディングを実装する方法を紹介します。
pandasライブラリのget_dummyiesを使用します。
import pandas as pd
# サンプルデータ
data = {'Color': ['Red', 'Blue', 'Green', 'Blue', 'Red']}
# データフレームの作成
df = pd.DataFrame(data)
# One-Hotエンコーディング
df_one_hot = pd.get_dummies(df, columns=["Color"])
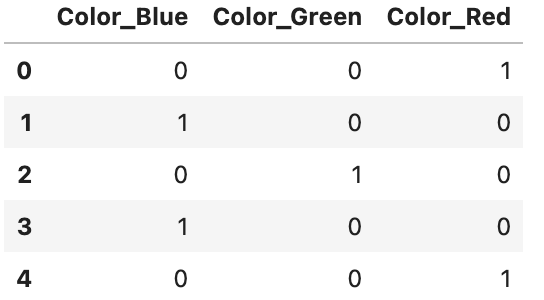
df_one_hot実行結果
特徴量スケーリング
特徴量スケーリングとは、特徴量ごとに異なるスケール(範囲)を統一するプロセスです。
特徴量スケーリングをすることで、効率的に学習でき、予測精度を向上させることができます。
主な特徴量スケーリングは以下の通りです。
- 標準化
- 正規化
標準化
標準化とは、各特徴量から平均を引き、標準偏差で割ることで、平均0、標準偏差1になるようにすることです。
計算式は以下の通りです。
\[ z = \frac{x – \mu}{\sigma} \]
Python 実践 標準化
Pythonを使用し、データを標準化する方法を紹介します。
scikit-learnライブラリを使用します。
サンプルコードは以下の通りです。
from sklearn.preprocessing import StandardScaler
import pandas as pd
# サンプルデータ
data = {'Feature1': [10, 20, 30, 40], 'Feature2': [100, 200, 300, 400]}
df = pd.DataFrame(data)
# 標準化
scaler = StandardScaler()
df_standardized = scaler.fit_transform(df)
df_standardized実行結果
array([[-1.34164079, -1.34164079],
[-0.4472136 , -0.4472136 ],
[ 0.4472136 , 0.4472136 ],
[ 1.34164079, 1.34164079]])もとのデータよりも0付近で値が収まっていることがわかります。
一方で、もとのデータはマイナスでないにもかかわらず、標準化することにより、マイナスになっているデータがあります。
本来のデータの意味を変えてしまっています。
次に紹介する正規化は、マイナスの値を取らずにデータをある範囲で収めることが可能です。
正規化(最小-最大スケーリング)
正規化とは、データを特定の範囲内に収束させる手法のことです。
正規化のうち、0〜1の範囲に収束させる方法を最小-最大スケーリングといいます。
最小-最大スケーリングの計算式は以下の通りです。
\[ x_{norm} = \frac{x_{i} – x_{min}}{x_{max} – x_{min}} \]
\(x_{min}\) : 最小値
\(x_{max}\) : 最大値
Python実践 正規化(最小-最大スケーリング)
Pythonを使用し、最小-最大スケーリングを実装する方法を紹介します。
scikit-learnライブラリを使用します。
サンプルコードは以下の通りです。
from sklearn.preprocessing import MinMaxScaler
# サンプルデータ
data = {'Feature1': [10, 20, 30, 40], 'Feature2': [100, 200, 300, 400]}
df = pd.DataFrame(data)
# 最小-最大スケーリング
scaler = MinMaxScaler()
df_minmax = scaler.fit_transform(df)
df_minmax
実行結果
array([[0. , 0. ],
[0.33333333, 0.33333333],
[0.66666667, 0.66666667],
[1. , 1. ]])データが0〜1の範囲に収まっていることがわかります。
まとめ
機械学習の前処理について、Pythonを使用した実装方法を交えて紹介しました。
前処理には以下があります。
- データクリーニング
- 特徴量エンコーディング
- 特徴量スケーリング
それぞれPythonを使用すると、ライブラリが用意されているので、簡単に実装することが可能です。
ここまで読んでくださりありがとうございます。