今回は、機械学習アルゴリズムの中でも予測精度が高く、扱いやすく人気のあるランダムフォレストについて紹介します。
ランダムフォレストの仕組みと合わせて、実際にPythonを使用し、ランダムフォレストのモデルを構築する方法を解説します。
動画で詳しく学習したい方はこちらもおすすめ
ランダムフォレストとは
決定木とバギングと呼ばれるアンサンブル学習を組み合わせたアルゴリズムです。
バギングとはブートストラップ法を使用し、複数のデータに対し、それぞれモデルを作成し、平均や多数決で決める方法です。
すなわちランダムフォレストは、決定木を複数使用し、精度を高めるアルゴリズムです。
その結果、決定木の弱点である過学習を抑えつつ、高い予測精度をもつモデルになるのです。
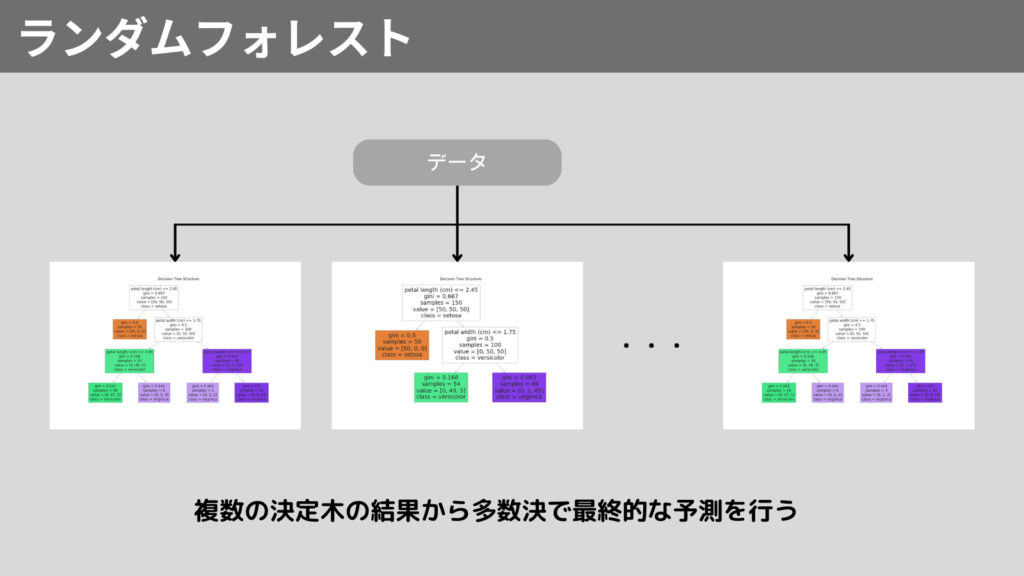
ランダムフォレストの仕組み
ランダムフォレストは以下ステップで動作します。
- ブートストラップ法によるデータサンプリング
- 特徴量の選択
- 複数の決定木の構築
- 平均または多数決
以降で詳しく説明していきます。
1. ブートストラップ法によるデータサンプリング
データからテストデータをランダムに抽出します。
このとき同じデータが複数回選ばれることを許容するため、少しずつ異なるテストデータを抽出します。
このプロセスを複数回繰り返すことで、複数のテストデータで決定木を作成するのです。
2. 特徴量の選択
決定木を構築するために、各テストデータに対し、特徴量を選択します。
これにより、特徴量の異なる複数の決定木を作成できます。
3. 複数の決定木の構築
上記のテストデータと特徴量を使用し、決定木を構築します。
4. 平均または多数決
複数の決定木から得られた予測結果から最終的な予測結果を求めます。
回帰問題の場合は平均、分類問題の場合は多数決で最終的な予測結果を決定します。
ランダムフォレストの特徴
ランダムフォレストのメリット・デメリットは以下の通りです。
メリット
- 高精度
複数の決定木を組み合わせることで、精度が向上 - 過学習を抑制
ランダムでテストデータを生成し、ある特定のデータに対して学習しないため、過学習を抑制可能
デメリット
- 処理負荷
複数の決定木を構築するため、学習に時間がかかる - 解釈性が低い
複数の決定木を組み合わせているので、モデルが複雑になり、単体の決定木よりも解釈性が低下
Python実践 ランダムフォレスト
それでは、Pythonを使用し、ランダムフォレストを実装してみましょう!
ランダムフォレストをPythonで実装するには、scikit-learnライブラリを使用します。
ランダムフォレストは以下方法で、モデルを作成します。
from sklearn.ensemble import RandomForestClassifier
モデル = RandomForestClassifier()
モデル.fit(X, y)
サンプルコードでランダムフォレストを実装してみます。
使用するデータは決定木で使用したデータを使います。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# サンプルデータの生成
X, y = make_blobs(n_samples=200, centers=3, random_state=6)
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 決定木モデルの作成と学習
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 境界線を描画するためのメッシュグリッドの作成
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# メッシュグリッドの各点でクラスを予測
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 境界線のプロット
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap='autumn') # 境界線を塗り分け
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap='autumn') # データ点
plt.title("Random Forest")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()実行結果
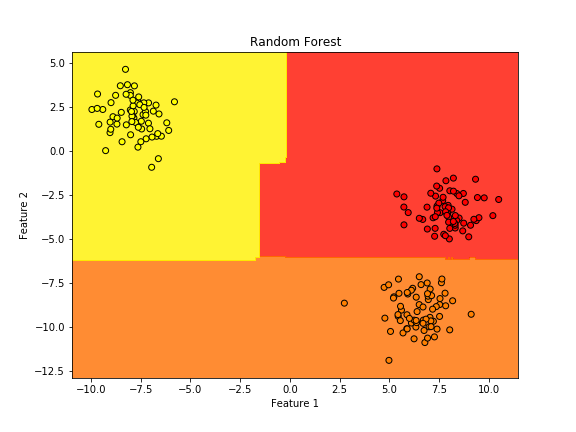
決定木のモデルで作成した境界線よりも折れ曲がった境界線になっていると思います。
これは、決定木よりも複雑に分類しているためです。
まとめ
今回は、機械学習アルゴリズムのひとつであるランダムフォレストについて紹介しました。
ランダムフォレストは、複数の決定木をランダムに構築することで、高い予測精度と過学習を抑制することが特徴です。
Pythonでランダムフォレストのモデルを生成する方法は以下です。
from sklearn.ensemble import RandomForestClassifier
モデル = RandomForestClassifier()
モデル.fit(X, y)
ここまで読んでくださりありがとうございます。