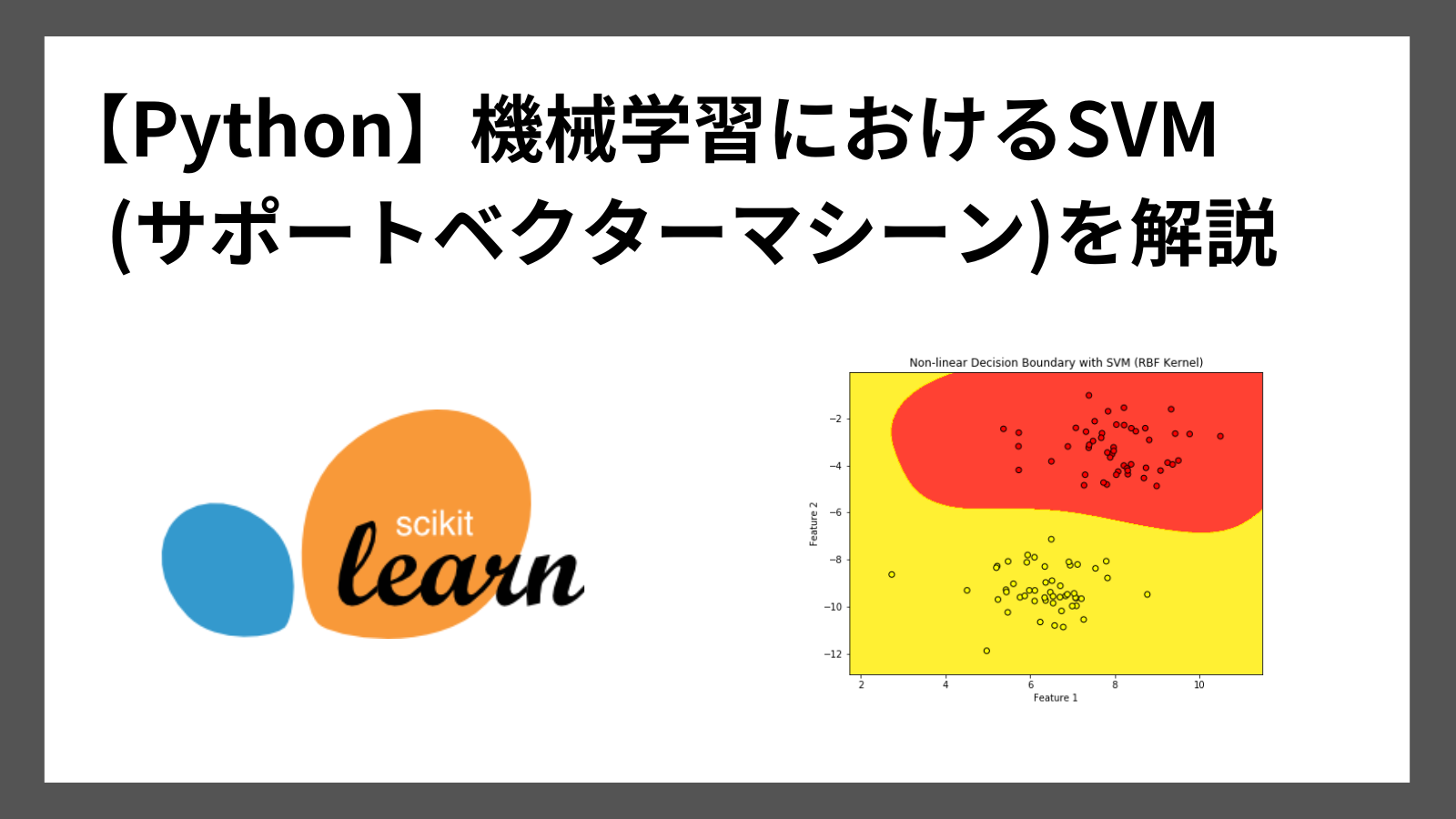
今回は、機械学習のアルゴリズムであるSVM(サポートベクターマシン)とは何か、Pythonで実装する方法を紹介します。
動画で詳しく学習したい方はこちらもおすすめ
SVM(サポートベクターマシン)とは
SVM(Support Vector Machine)は、教師あり学習の主に分類問題に使用される機械学習アルゴリズムです。主な用途は、音声認識や画像認識の分野です。
サポートベクターから境界線(決定境界線)の距離(マージン)を最大にとる手法のことをいいます。
サポートベクターとは、決定境界線から最も近い点のことです。
また、SVMはカーネル法という手法を用いて、非線形のデータも分析することが可能です。
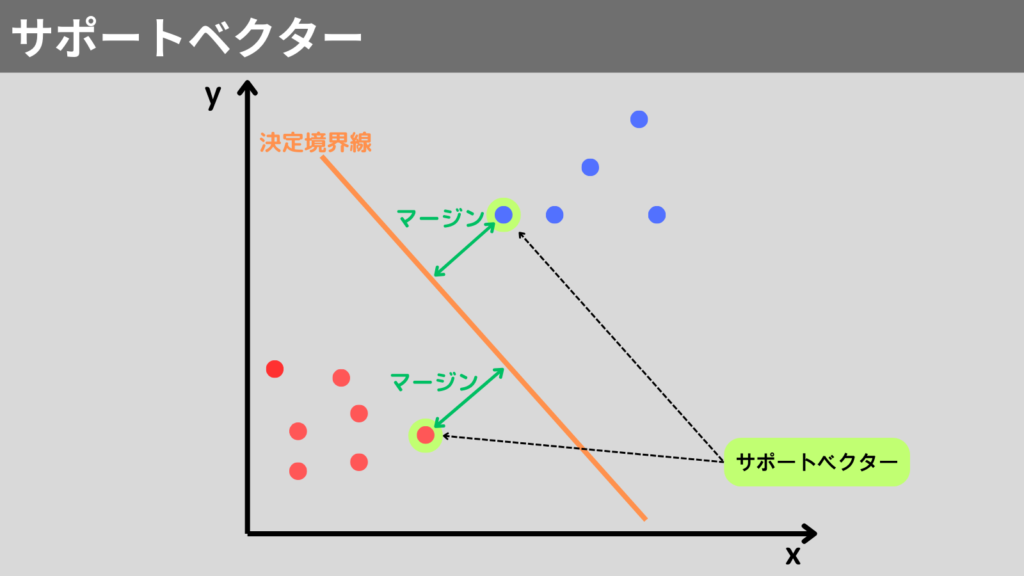
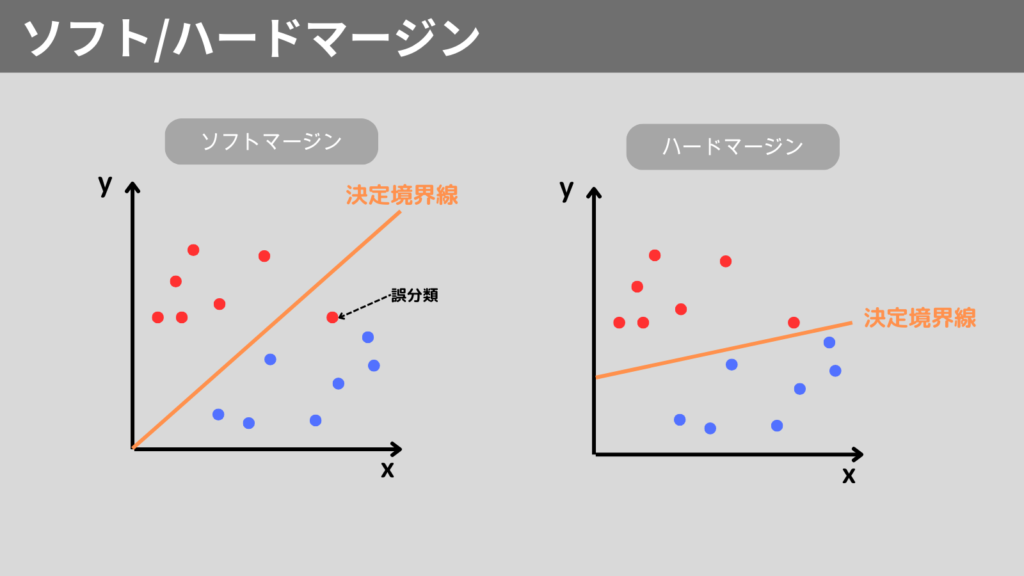
ソフト・ハードマージン
決定境界線を決める方法として、ソフトマージン法、ハードマージン法があります。
ソフトマージン法は、誤分類を許容する方法で、ハードマージン法は、誤分類を許容しない方法です。
ハードマージンは、誤分類を許容しないため、完全に分類できるデータでないと適用できません。
一方で、ソフトマージンであれば、誤分類が許容されるため、外れ値などにも対応できます。
カーネル法を用いたSVM
カーネル法を用いることで、非線形のデータについて分析が可能です。
カーネル法とは、簡単にいうと、低次元のデータを高次元に変換することです。
高次元にすることで、低次元で見えてなかった分類方法を見つけ出すのです。
SVMの特徴
SVMのメリット・デメリットをまとめると以下の通りです。
メリット
- 過学習が起こりにくい
- 非線形も分類可能
デメリット
- 計算量が多い
- スケーリングが必要
Python実践 SVM
それでは、Pythonを使用し、SVMを実装してみましょう!
SVMをPythonで実装するには、scikit-learnライブラリを使用します。
SVMは以下方法で、モデルを作成します。
from sklearn.svm import SVC
モデル = SVC()
モデル.fit(X, y)
以下は、PythonでSVMを実装したサンプルコードです。
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.svm import SVCa
import matplotlib.pyplot as plt
# データの生成
X, y = make_blobs(n_samples=100, centers=2, random_state=6)
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# SVMモデルの作成
model = SVC(kernel='rbf', C=1, gamma=0.5) # RBFカーネルを使用
model.fit(X, y)
# 境界線を描画するためのメッシュグリッド作成
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# 各点の分類を予測
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# データと決定境界のプロット
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap='autumn') # 境界線
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap='autumn') # データ点
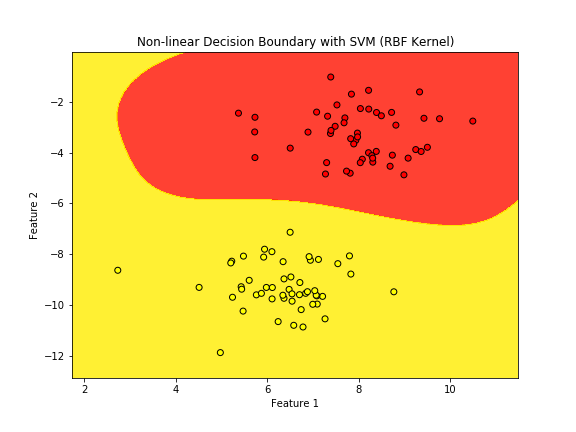
plt.title("Non-linear Decision Boundary with SVM (RBF Kernel)")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
実行結果
まとめ
機械学習の基本的なアルゴリズムのひとつである、SVM(サポートベクターマシーン)を紹介しました。
カーネル法を用いて、非線形のデータに対しても分類可能なことが特徴的です。
以下方法で、SVMを簡単に実装できます。
from sklearn.svm import SVC
モデル = SVC()
モデル.fit(X, y)
ぜひみなさんも試してみてください!
ここまで読んでくださりありがとうございます。