今回は、機械学習のパイプラインを用いてグリッドサーチを実施する方法を解説します。
グリッドサーチとパイプラインそれぞれについて簡単に解説したあとに、お互いを組み合わせる方法を紹介します。
また、Pythonを使用してグリッドサーチとパイプラインを組み合わせて実装する方法も紹介します。
動画で詳しく学習したい方はこちらもおすすめ
グリッドサーチとは
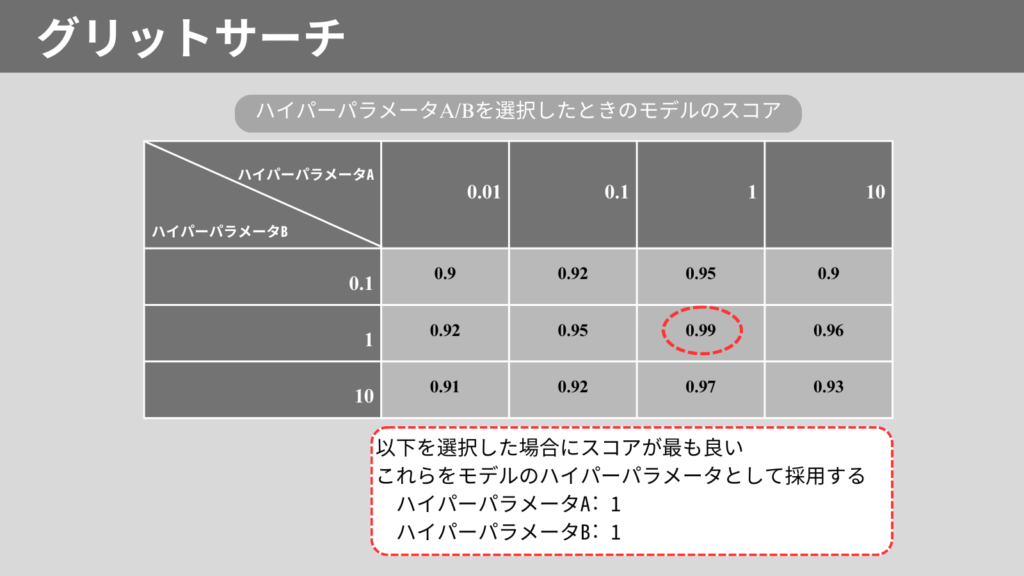
グリッドサーチ(Grid Search)は、最適なハイパーパラメータを見つけるための手法です。
複数のハイパーパラメータの組み合わせを網羅的に探索します。
すべての組み合わせを試行し、最も評価の良いパラメータを見つけます。
グリッドサーチの実装方法
グリッドサーチの実装方法を簡単に紹介します。
sklearnのmodel_slectionモジュールを使用します。
from sklearn.model_selection import GridSearchCV
GridSearchCV(estimator, param_grid, cv, scoring, n_jobs)
GridSearchCVのパラメータの説明は以下の通りです。
| パラメータ | 説明 | デフォルト |
|---|---|---|
| estimator | モデル | 必須 |
| param_grid | 辞書型のハイパーパラメータ | 必須 |
| cv | 交差検証の分割数 | 5 |
| scoring | 評価指標(accuracy=正解率, precision=適合率… ) | None |
| n_jobs | 並列処理数(-1 で全CPU使用) | None |
パイプラインとは
機械学習におけるパイプラインは、データ収集からモデルのチューニングまでの一連の流れを自動化するプロセスのことをいいます。
これにより、機械学習プロセスの簡略化や再現性の向上が見込まれます。

パイプラインの実装方法
パイプラインの実装方法を簡単に紹介します。
Pythonでパイプラインを実装する方法は以下の通りです。
from sklearn.pipeline import Pipeline
Pipeline(steps, memory, verbose)
Pipelineのパラメータの説明は以下の通りです。
| パラメータ | 説明 | デフォルト |
|---|---|---|
| steps | リスト形式で処理を指定 | 必須 |
| 処理はタプルで(名前, ステップ)指定 | – | 必須 |
| memory | キャッシュ使用するかを指定 | None |
| verbose | 各ステップ実行時に詳細な出力をするか | None |
パイプラインを用いたグリッドサーチ
パイプラインとグリッドサーチを組み合わせることで、前処理とハイパーパラメータのチューニングが同時に行えます。
通常のグリッドサーチでは、ハイパーパラメータのチューニングしか行いません。
パイプラインを用いることで、標準化などの前処理した結果を使用して、ハイパーパラメータをチューニングできます。
Python実践 パイプラインを用いたグリッドサーチ
それでは、Pythonを使用しパイプラインを用いたグリッドサーチを実装してみましょう!
以下方法で、パイプラインとグリットサーチを組み合わせて実装します。
GridSearchCV の引数stepsにPipeline で作成したパイプラインを指定します。
pipeline = Pipeline([
(‘scaler’, StandardScaler()),
(‘svm’, SVC())
])
GridSearchCV(steps=pipeline, param_grid)
サンプルコードは以下の通りです。
Pipeline を使ってデータの前処理(標準化)と SVM の分類を行い、GridSearchCV で最適なパラメータを探索します。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
pipeline = Pipeline([
('scaler', StandardScaler()),
('svm', SVC())
])
param_grid = {
'svm__C': [0.1, 1, 10],
'svm__kernel': ['linear', 'rbf'],
'svm__gamma': ['scale', 'auto']
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
print("Best parameters:", grid_search.best_params_)
print("Best score:", grid_search.best_score_)
実行結果
Best parameters: {'svm__C': 0.1, 'svm__gamma': 'scale', 'svm__kernel': 'linear'}
Best score: 0.9583333333333334まとめ
機械学習のパイプラインを用いてグリッドサーチを実施する方法を紹介しました。
パイプラインとグリッドサーチを組み合わせることで、前処理とハイパーパラメータのチューニングが同時に行えます。
Pythonで実装する方法は以下の通りです。
pipeline = Pipeline([
(‘scaler’, StandardScaler()),
(‘svm’, SVC())
])
GridSearchCV(steps=pipeline, param_grid)
ここまで読んでくださりありがとうございます。








