
今回は、統計学における重要なプロセスである区間推定について説明します。
そのなかでも比率の区間推定をPythonを使用し、求める方法を紹介します。
推定
統計学における推定とは、標本データから母集団のデータを推測するプロセスのことです。
推定には2種類あります。
- 点推定
- 区間推定
以降で詳しく説明していきます。
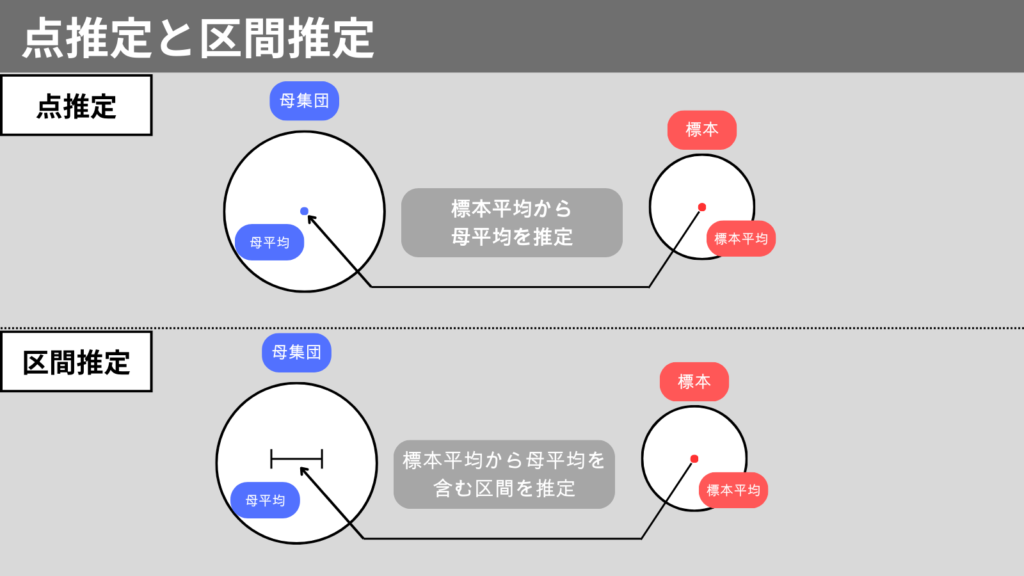
点推定
点推定は母集団のパラメータをある値で推定する方法です。
例えば、標本平均を用いて母集団の平均を推定することなどがあります。
点推定は直感的に理解しやすいですが、一方で推定値が正確だと言い切れないことが欠点です。
標本の平均が母集団の平均と一致することは、確率が低いですよね。
この点推定の不確実性という欠点をカバーするのが区間推定です。
区間推定
区間推定とは、母集団のパタメータがある範囲内にあることを推定する方法です。
この範囲を信頼区間と呼びます。
95%の信頼区間などと言ったりしますが、この95%というのは100回区間推定を施行した内、
95回は推定した区間に母集団のパラータが含まれることを意味しています。
母比率の区間推定
母比率の区間推定は、標本データの比率から母集団の比率を区間推定する方法です。
例えば、ある製品の満足度調査として、100人にアンケートを取りその結果から顧客全体の満足度を推定する方法です。
Pythonで比率の区間推定する方法
それでは、Pythonで比率の区間推定を実装していきます。
今回は二項分布を使って比率の区間推定をする方法を紹介します。
Pythonで区間推定をするにはSciPyライブラリのstatsモジュールの以下を使用します。
binomが二項分布を指し、intervalが区間推定を指しています。
stats.binom.interval(alpha, n, p)
alpha:信頼区間(0.95=95%など) n: サンプルサイズ p: 標本比率
下限値と上限値をタプルで返します。
tipsのデータセットを使用したサンプルコードは以下の通りです。
import pandas as pd
import seaborn as sns
from scipy import stats
alpha = 0.95 # 信頼区間
n = 50 # 標本サイズ
# データセットをロード
df = sns.load_dataset('tips')
# 標本の抽出
sample_df = df.sample(n)
# 標本の比率
smoker_ratio = len(sample_df[sample_df['smoker']=='Yes']) / n
# 母集団の比率を推定
lower, upper = stats.binom.interval(alpha, n, smoker_ratio)
# 比率に変換
lower_ratio = lower / n
upper_ratio = upper / n
print(f"喫煙者の95%信頼区間: ({lower_ratio}, {upper_ratio})")
# 母集団の比率
p_smoker_ratio = len(df[df['smoker']=='Yes']) / len(df)
print(f"母集団の比率:{p_smoker_ratio:.2f}")実行結果
喫煙者の95%信頼区間: (0.18, 0.44)
母集団の比率:0.38これで喫煙者の比率を95%の信頼区間で求めることができました。
母集団の比率が求めた区間に収まっていることがわかります。
まとめ
区間推定の説明、およびPythonを使用し比率の区間推定をする方法を紹介しました。
区間推定は統計学でよく使用する手法です。
ぜひ区間推定のやり方をマスターしてみてください!
ここまで読んでくださりありがとうございます。
参考
おすすめ教材
米国データサイエンティストが教える統計学超入門講座【Pythonで実践】

他のUdemyの講座が気になる方はこちら










