
今回は、標準化する方法を紹介します。
目次
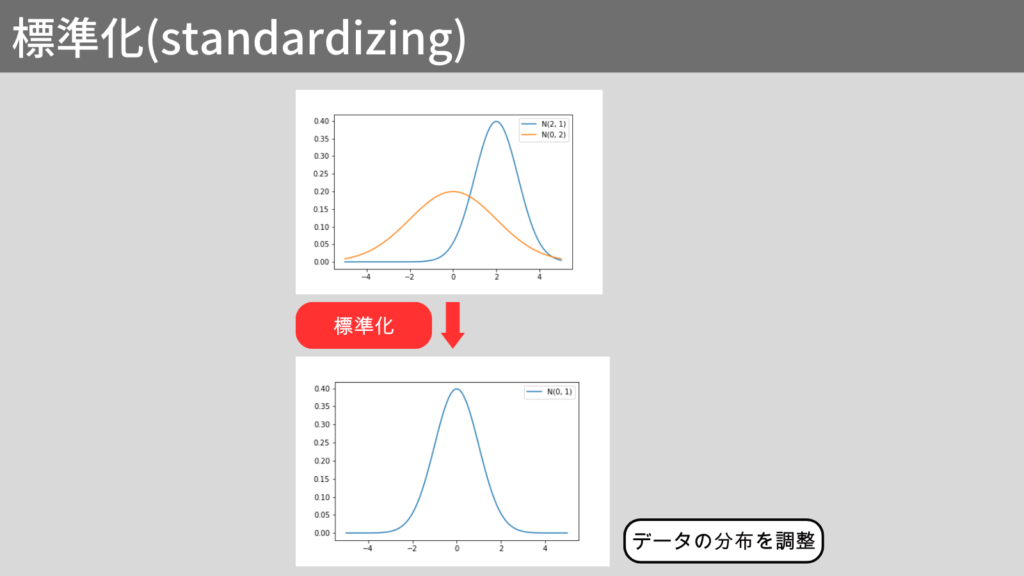
標準化とは
標準化(standardizing)は平均を0、標準偏差を1にする変換です。
標準化を式で表すと以下です。
\[ z = \frac{x – \mu}{\sigma} \]
\( x \): 確率変数
\( \mu \): 平均
\( \sigma \): 標準偏差
標準化された値をz値といいます。
正規化との違い
標準化と似たようなデータの変換方法として、正規化があります。
正規化は、データを0から1または-1から1の間に収まるようにデータを変換しています。
このように、正規化はデータが特定の範囲に収まることが必要な場合のデータ処理に適しています。
一方で標準化は、データの範囲は決まっていないので、外れ値の影響を受けにくいです。
Pythonで標準化する方法
Pythonを標準化する方法を説明します。
sklearnライブラリのStandardScalerというクラスを使用します。
以下方法で、データを標準化します。
# StandardScalerのインポート
from sklearn.preprocessing import StandardScaler
# StandardScalerのインスタンスを作成
scaler = StandardScaler()
# データを標準化
standardized_data = scaler.fit_transform(data)サンプルコードは以下の通りです。
import numpy as np
from sklearn.preprocessing import StandardScaler
# データの例
data = np.array([
[50, 2, 3.5],
[60, 1, 8.0],
[70, 2.5, 6.5],
[80, 2, 7.0]
])
# StandardScalerのインスタンスを作成
scaler = StandardScaler()
# データを標準化
standardized_data = scaler.fit_transform(data)
print(standardized_data)実行結果
[[-1.34164079 0.22941573 -1.63978318]
[-0.4472136 -1.60591014 1.04349839]
[ 0.4472136 1.14707867 0.1490712 ]
[ 1.34164079 0.22941573 0.4472136 ]]これで標準化できました!
まとめ
今回は、Pythonで標準化する方法を紹介しました。
sklearnライブラリのStandardScalerというクラスを使用し、データを標準化しました。
標準化の前にインスタンスを作成するというポイントを理解してもらえれば、簡単に標準化できると思います。
ここまで読んでくださりありがとうございます。
参考
おすすめ教材
米国データサイエンティストが教える統計学超入門講座【Pythonで実践】

![]()
他のUdemyの講座が気になる方はこちら










